什么是调度
调度器决定哪个线程被允许在任何时间点上执行;这个线程被称为当前线程。
在不同的时间点有机会改变当前线程的身份。这些点被称为重新安排点。一些潜在的重排点是:
- 从运行状态过渡到暂停或等待状态,例如通过k_sem_take()或k_sleep()。
- 过渡到准备状态,例如通过k_sem_give()或k_thread_start()。
- 处理完中断后返回到线程上下文
- 调用k_yield()
当线程主动发起将自身转换为暂停或等待状态的操作时,它就会进入睡眠状态。
每当调度器改变了当前线程的身份,或者当前线程的执行被ISR所取代时,内核会首先保存当前线程的CPU寄存器值。当线程后来恢复执行时,这些寄存器的值会被恢复。
调度器是如何工作的?
内核的调度器选择最高优先级的就绪线程作为当前线程。当存在多个相同优先级的就绪线程时,调度器会选择等待时间最长的那个。
注意:ISR的执行要优先于线程的执行。除非中断被屏蔽了,否则当前的线程可以在任何时候被ISR取代。
内核在构建时可以选择几种就绪队列的实现方式之一。这种选择是一种权衡:
- 代码大小
- 恒定系数的运行时间开销
- 当涉及到许多线程时的性能扩展
你的Kconfig文件(prj.conf)应该包含以下内容之一(或者它将默认为简单的链接列表)。
队列类型:
- 简单链接列表准备队列(CONFIG_SCHED_DUMB)
- 简单无序列表
- 对于单线程来说,具有非常快的恒定时间性能
- 代码大小非常低
- 对有以下情况的系统有用:
- 有限的代码大小
- 在任何时候都有少量的线程(<=3)。
- 红/黑树就绪队列(CONFIG_SCHED_SCALABLE)
- 红/黑树
- 较慢的恒定时间插入和移除开销
- 需要额外的2Kb代码
- 可以干净利落地扩展到成千上万的线程
- 适用于有以下情况的系统:许多并发的可运行线程(>20个左右)。
- 传统的多队列就绪队列(CONFIG_SCHED_MULTIQ)
- 经典的列表阵列,每个优先级一个(最多32个优先级)。
- 与 "dumb "调度器相比,其代码开销很小
- 在0(1)时间内运行,恒定系数很低
- 需要相当大的RAM预算来存储列表头
- 与截止日期调度和SMP亲和性不兼容
- 有少量线程的系统(但通常DUMB已经足够好了)。
- 可扩展的wait_q实现(CONFIG_WAITQ_SCALABLE)。
- 简单的链接列表wait_q (CONFIG_WAITQ_DUMB)
线程优先级是如何工作的?
线程的优先级是整数值,可以是负数,也可以是非负数。从数字上看,较低的优先级优先于较高的值(-5>6)。
调度器根据每个线程的优先级来区分两类线程。
- 协作(cooperative)线程有负的优先级值。一旦它成为当前线程,合作线程就一直是当前线程,直到它执行了使其unready的动作。
- 可抢占的线程有非负的优先权值。一旦成为当前线程,如果协作线程或更高或同等优先级的可抢占线程准备就绪,可抢占线程可以在任何时候被取代。
线程的初始优先级值可以在该线程启动后被向上或向下改变。因此,可抢占的线程有可能成为协作线程,反之亦然。
内核支持几乎无限数量的线程优先级。配置选项CONFIG_NUM_COOP_PRIORITIES和CONFIG_NUM_PREEMPT_PRIORITIES为每一类线程指定了优先级的数量,导致以下可用的优先级范围:
- 协作性线程:(-CONFIG_NUM_COOP_PRIORITIES)到-1
- 抢占式线程: 0到(CONFIG_NUM_PREEMPT_PRIOTIES-1)
什么是协作式时间切分?
因此,如果协作线程执行冗长的计算,它可能会导致其他线程的调度出现不可接受的延迟,包括那些更高的优先级。
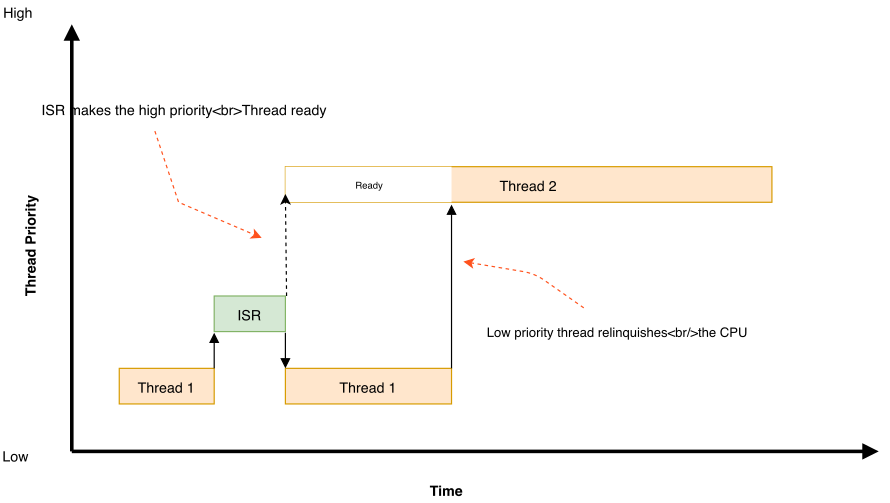
为了克服这样的问题,协作线程可以不时地自愿放弃CPU,以允许其他线程执行。线程可以通过两种方式放弃CPU:
- 调用k_yield()将线程放在调度器的就绪线程优先级列表的后面,然后调用调度器。所有优先级高于或等于该线程的就绪线程被允许在该线程被重新安排之前执行。如果没有这样的线程存在,调度器会立即重新安排该线程,而不进行上下文切换。
- 调用k_sleep()使线程在指定的时间段内unready。然后,所有优先级的就绪线程都被允许执行;然而,并不保证优先级低于休眠线程的线程会在休眠线程再次变得就绪之前实际被调度。
什么是抢占式时间切分?
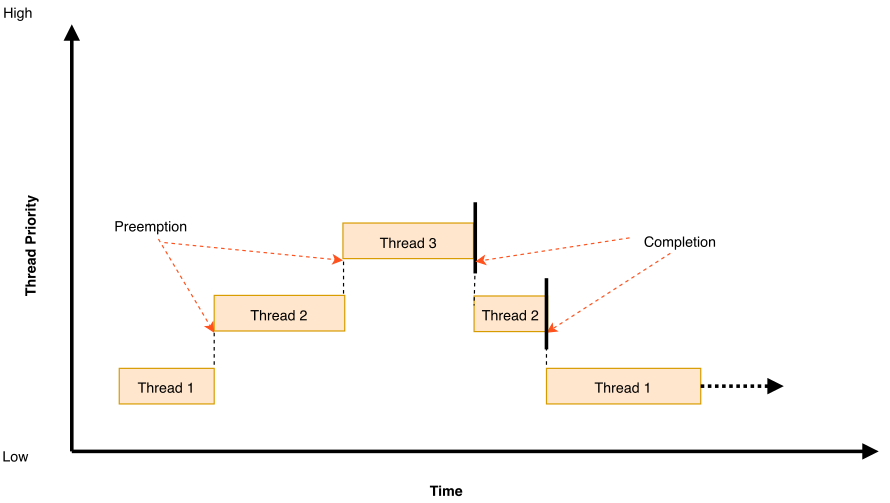
图中显示了同等优先级的线程相互抢占的情况
抢占式线程可以执行合作性的时间切分(如上所述),或者利用调度器的时间切分能力来允许其他相同优先级的线程执行。
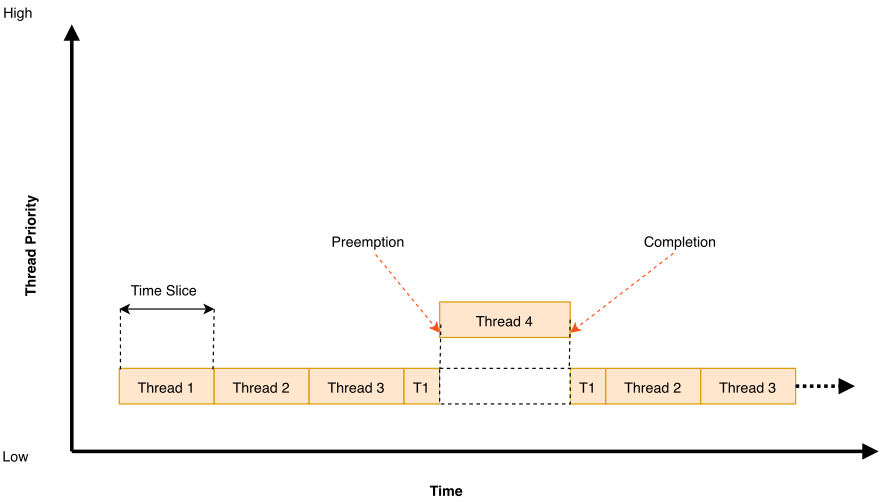
调度器将时间划分为一系列的时间片,这里的时间片是以系统时钟刻度来衡量的。时间片的大小是可配置的,但这个大小可以在应用程序运行时改变。
在每个时间片结束时,调度器会检查当前线程是否是可抢占的,如果是,就隐式地代表线程调用k_yield()。这给了其他相同优先级的准备好的线程在当前线程再次被调度之前执行的机会。如果没有相同优先级的线程准备好了,那么当前线程仍然保留。
优先级高于指定限制的线程不受抢占式时间切分的影响,也不会被同等优先级的线程抢占。这允许应用程序只在处理对时间不太敏感的低优先级线程时使用抢占式时间切分。
注意:内核的时间切分算法并不能确保一组同等优先级的线程获得公平的CPU时间,因为它并不衡量线程实际得到的执行时间的多少。然
不希望在执行关键操作时被抢占的可预选线程可以通过调用k_sched_lock()指示调度器暂时将其作为协作线程。这可以防止其他线程在执行关键操作时受到干扰。
一旦关键操作完成,可抢占的线程必须调用k_sched_unlock()来恢复其正常的、可抢占的状态。
如果线程调用k_sched_lock(),并随后执行了unready的操作,调度器将把锁定的线程切换出来,并允许其他线程执行。当锁定的线程再次成为当前线程时,它的不可抢占状态将被保持。
注意:对于可抢占的线程来说,锁定调度器是一种比将其优先级改为负值更有效的防止抢占的方法。
实例:协作式时间切分
线程_1,即使优先级较低,也不会让给线程_2(直到完成)。
#include <zephyr/zephyr.h>
/* size of stack area used by each thread */
#define STACKSIZE 1024
#define PRIORITY_THREAD_1 (-1)
#define PRIORITY_THREAD_2 (-2)
K_THREAD_STACK_DEFINE(thread_1_stack_area, STACKSIZE);
static struct k_thread thread_1_data;
K_THREAD_STACK_DEFINE(thread_2_stack_area, STACKSIZE);
static struct k_thread thread_2_data;
void thread_1(void *dummy1, void *dummy2, void *dummy3)
{
ARG_UNUSED(dummy1);
ARG_UNUSED(dummy2);
ARG_UNUSED(dummy3);
int i =