Ŀ¼

ʾ�������й��ڣ�https://www.github.com/dashnowords/blogs
������ַ������ʷס�ڴ�ǰ�ˡ�ԭ������Ŀ¼
��Ϊ��������ַ������Ҫ��ǰ�˴������ָ�ϡ�
һ. ����
clusterģ����node.js������ʵ�ֺ�������̵�ģ�顣�����node.jsӦ�ó����ǵ��̵߳����̵ģ���Ҳ��ζ�������ѳ�����÷��������CPU�����ܣ���clusterģ�����Ϊ�˽����� ����ģ���ʹ��node.js��������Զ��ʵ������ķ�ʽ�����ڲ�ͬ�Ľ����У���������եȡ�����������ܡ�node.js�ڹٷ�ʾ��������ʹ��workerʵ������ʾ������fork�����ӽ��̣�ʹ��ǰ�˿�������ѧϰ�����зdz���������������е�workerʵ�ֵĶ��̻߳�����Ϊ���������֣����Ǻ�node�ٷ��ĵ�ʹ��һ�µ����ƣ��ü�Ⱥ�е�master��worker�����������̺������̣���worker_threads�����������̡߳�
node.js������ģ���У�master�������൱��һ������ͷ�����ܼ����˿ڣ���slave���̱�����ʵ�ʵ�����ִ�У�������������������ij�ַ�ʽ������ѭ���ַ���worker�����������������ϣ�������ݵ�ǰ����worker���̵ĸ���״�����������Ϣ����ѡ�������̣�Ч��Ӧ�ñ�ֱ��ѭ������Ҫ���ߣ���node.js�ĵ����������ַ�ʽ�����ܵ�����ϵͳ���Ȼ��Ƶ�Ӱ�죬��ʹ�÷ַ���ò��ȶ������ԻὫ"ѭ����"��ΪĬ�ϵķַ����ԡ�
����clusterģ����÷���APIϸ�ڣ�����ֱ�Ӳο��ٷ��ĵ���Node.js������V10.15.3/cluster����
��. �߳������
��Ҫ���������÷��������ܣ�������Ҫ�˽⡰�̡߳���thread���͡����̡���process�����������
���������CPU��ִ�м�������ģ������ֻ��һ��CPU����ô��̨���������е�����������ִ�С����ȿ����մ���ִ�е�ԭ��һ����һ��ִ������Ҳ�������ݲ���ԭ��ͬ��ִ�ж�����������ͬ��ִ��ʱ��CPU������ڶ���߳�֮������л����л��̵߳�ͬʱҪ�л���Ӧ����������ģ���ͻ���ɶ����CPU��Դ���ģ����Ե��߳������dz���ʱ���߳��л������ͻ��˷Ѵ�����CPU��Դ�������ִ��һ�������ͬʱ��CPU���ڴ涼���г����ʣ�࣬�Ϳ���ͨ��ij�ַ�ʽ������ȥִ����������
����Խ����̡߳�������һ���������ġ����̡���
������ڲ���ϵͳ�д��������������������ǩ�¾Ϳ��Կ�������ͼ��ʾ����
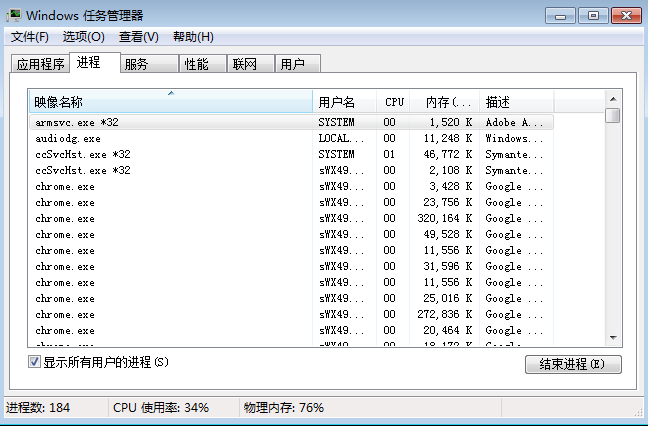
���ǿ��Կ���ÿһ��������������һ���µĽ��̣������˲���������chromeЧ�ʸߵ�ԭ����ʲô��û˵��������һ�����ȸ������Դ���뵥Ԫ������֮��ʹ�ò�ͬ���ڴ�������ֱ�ӹ������ݣ�ֻ��ͨ�������ͨѶ������ͨѶ����������Ҫʹ���µ��ڴ��������Ĵ������ٺ��л���Զ��Զ�����ʱ�����ĺô����ǽ���֮���ǻ������ģ�����Ӱ�죬���������һ��������һ������Ϸ����������Ϊ����������ͻȻ����һ�������֣��������Ϸ��Ľ�ɫ�����������ˡ�
������һ�����������ǩ��
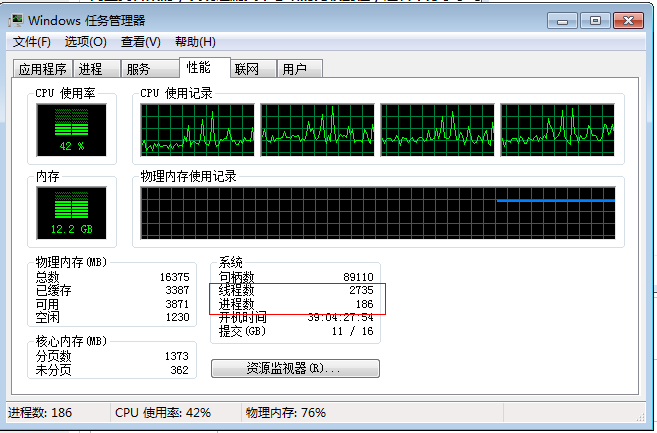
���Կ����߳�����Զ���ڽ������ġ����̡߳�ͨ�������ڵ��������̡������CPU�������ʣ�����һ�����ȸ�ϸ����Դ���ȵ�λ���������״��������٣���ͬһ�������ڵ��̹߳��������������̵��ڴ棬����Ҳ��ʵ���˹������ݣ����̵߳ı��Ҫ���Ӹ��ӣ����ڹ������ݣ�����߳�֮�䴫��ָ��Ȼ�����ͬһ����Դ���ͱ��뿼�ǡ�ԭ�Ӳ������͡����������⣬��������������ˣ�����������ݵĿ������ֻ�����ڴ��˷ѣ������߳��쳣���ᱻ���룬���ᵼ�����������쳣��
�̺߳ͽ��̵����֪ʶ�漰���ײ����ϵͳ�����ݣ������������ޣ��ȷ�����ô�ࣨ��Ķ��������ˣ���Ҫ����������
��. clusterģ��Դ�����
Դ���и����Ƚϳ�������ʹ�ô��д����۵��Ĺ���������
3.1 ��
clusterģ����÷��������������ӣ��ٷ�������ʾ���������ģ�
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`������ ${process.pid} ��������`);
// �����������̡�
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`�������� ${worker.process.pid} ���˳�`);
});
} else {
// �������̿��Թ����κ� TCP ���ӡ�
// �ڱ������У��������� HTTP ��������
http.createServer((req, res) => {
res.writeHead(200);
res.end('�������\n');
}).listen(8000);
console.log(`�������� ${process.pid} ������`);
}3.2 ���
clusterģ��������/lib/cluster.js������Ĵ���ܼ�
'use strict';
const childOrMaster = 'NODE_UNIQUE_ID' in process.env ? 'child' : 'master';
module.exports = require(`internal/cluster/${childOrMaster}`);���Կ�����������̶���Ļ�����������NODE_UNIQUE_ID�������������internal/cluster/child.jsģ���������������internal/cluster/master.jsģ������������node���������ڽ����ӽ��̹���ʱ�ı�ʶ������Ĵ����п��Կ���������cluster.fork( )����һ���ӽ���ʱ����һ������ID����ʽ�����������������
3.3 ������ģ��master.js
��������node����Ŀ϶������̣߳���ô���Ǵ�master.js���ģ�鿪ʼ�����ù����۵�һ�´������һ�£�
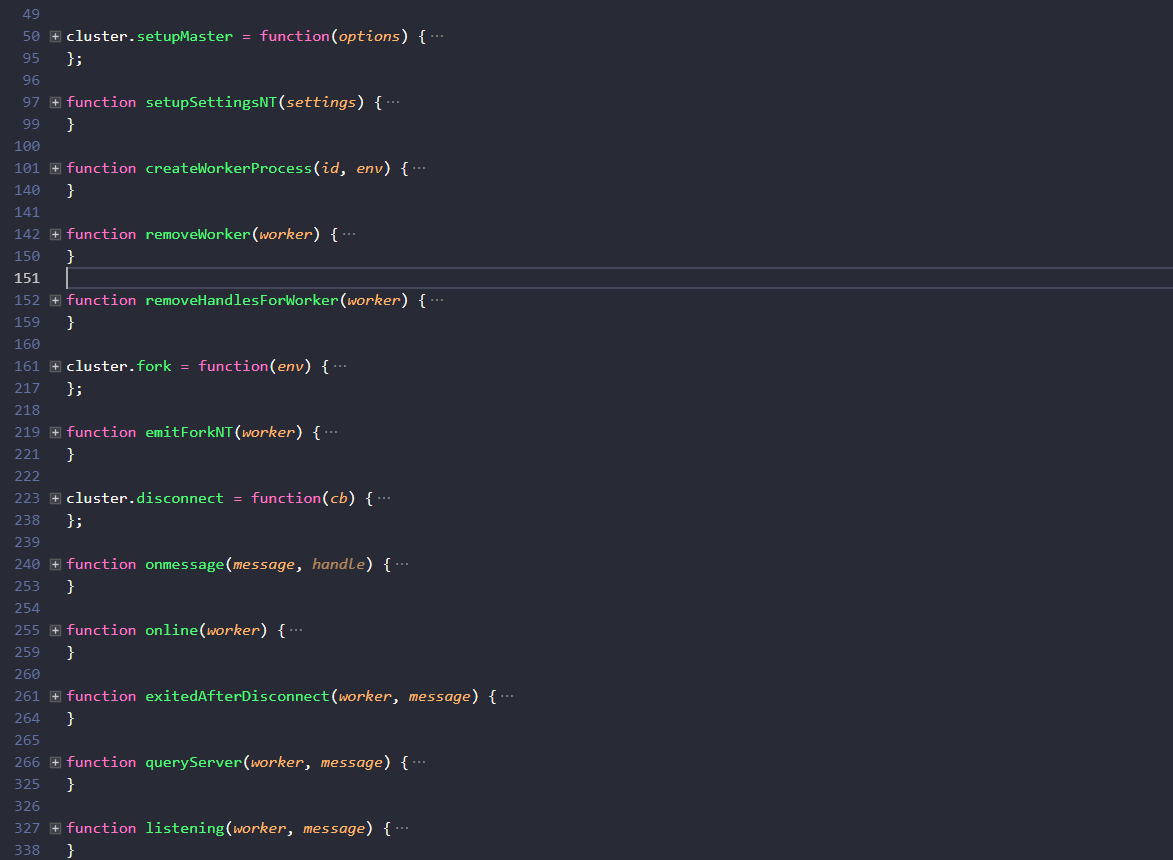
���Կ�������ģ�������⣬clusterģ����Ⱪ¶�ķ���ֻ������3���������Ķ�����������ڲ����ܵģ�
setupMaster(options )-��forkʱĬ������fork( )-�����ӽ���disconnect( )- �Ͽ��������ӽ��̵�����
���ǰ��չٷ�ʾ������·�����Ķ�����cluster.fork( )����������161-217�У�һ�������۵���������ȫò��
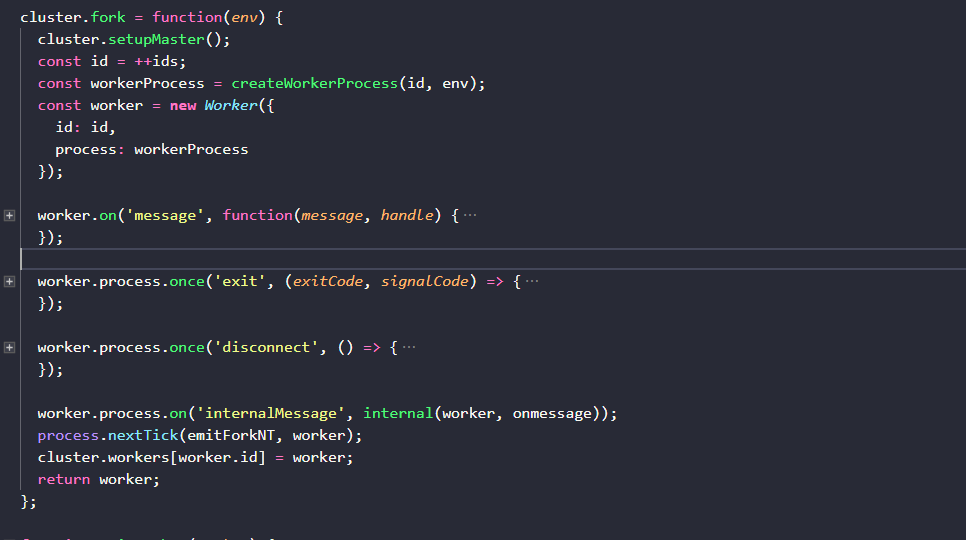
���Կ���cluster.fork( )ִ��ʱ�������¼������飺
1.�������̲߳���
2.����һ����������id(����ǰ���ᵽ��NODE_UNIQUE_ID)�ͻ�����Ϣenv������һ��worker�̵߳�process����
3.��id���µ�process������Worker�����������µ�worker����ʵ��
4