元素的转化操作
为了方便,代码在 pyspark 中展示:
# map()
# map() 的返回值类型不需要和输入类型一样
>>> nums = sc.parallelize([1, 2, 3, 4])
>>> squared = nums.map(lambda x: x * x).collect()
>>> for num in squared:
... print "%i " % (num)
...
1
4
9
16
# flatMap()
# 给flatMap() 的函数被分别应用到了输入RDD 的每个元素上。
# 返回的是一个返回值序列的迭代器。
#
>>> lines = sc.parallelize(["hello world", "hi"])
>>> words = lines.flatMap(lambda line: line.split(" "))
>>> words.first()
'hello'
map() 和 flatmap() 区别如下:
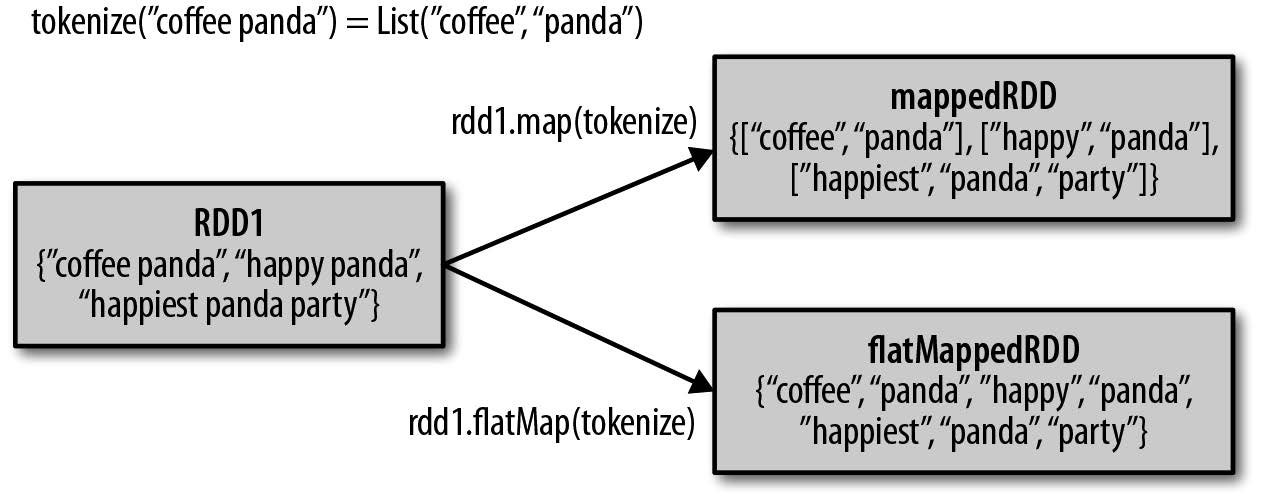
伪集合操作
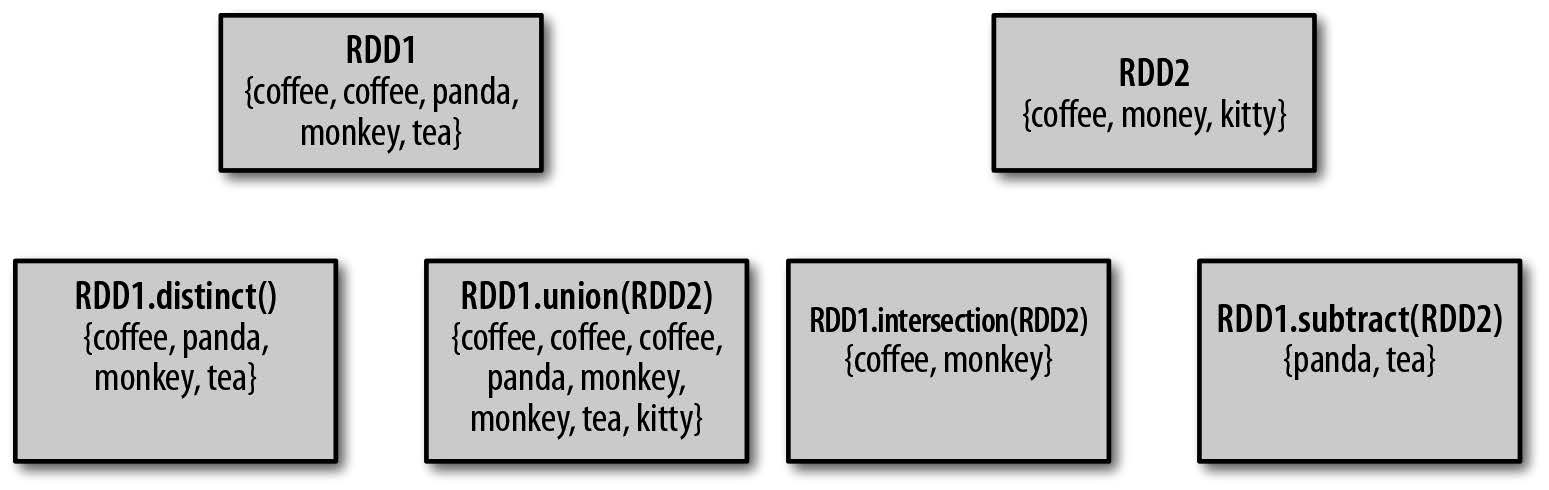
RDD 不算是严格意义上的集合,但是一些类似集合的属性让它能够支持许多集合操作,下图展示了常见的集合操作:
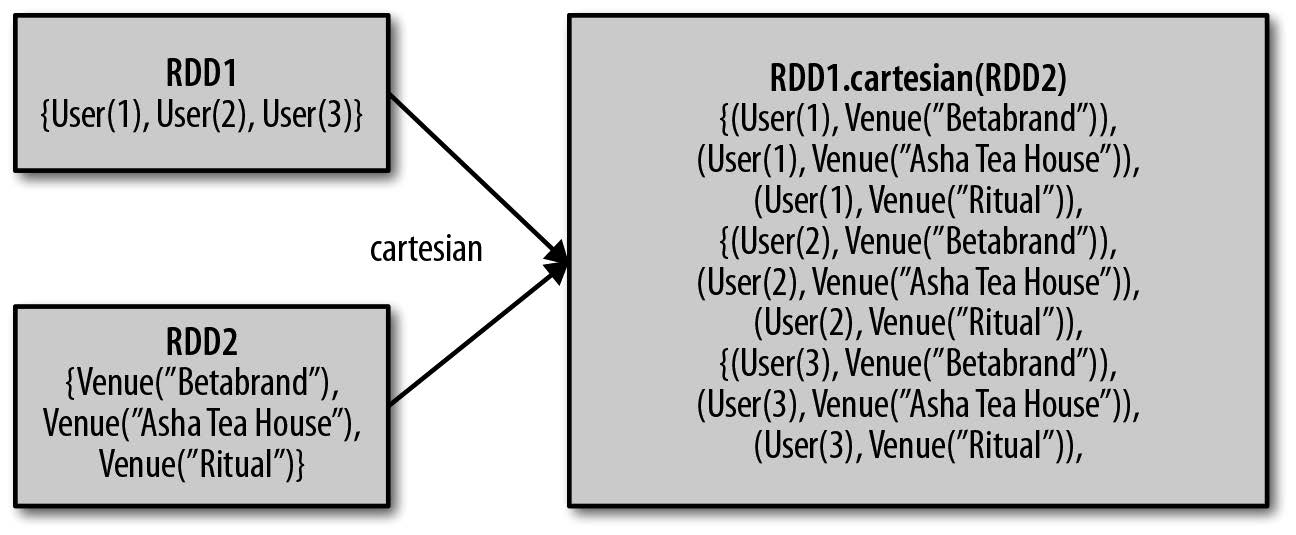
此外,RDD 还支持笛卡尔积的操作:
以下对基本 RDD 的转化操作进行梳理:
| map() |
将函数应用于RDD 中的每个元
素,将返回值构成新的RDD |
rdd.map(x => x + 1) |
{2, 3, 4, 4} |
| flatMap() |
将函数应用于RDD 中的每个元
素,将返回的迭代器的所有内
容构成新的RDD。通常用来切
分单词 |
rdd.flatMap(x => x.to(3)) |
{1, 2, 3, 2, 3, 3, 3} |
| filter() |
返回一个由通过传给filter()
的函数的元素组成的RDD |
rdd.filter(x => x != 1) |
{2, 3, 3} |
| distinct() |
去重 |
rdd.distinct() |
{1, 2, 3} |
| sample(withReplacement, fraction, [seed]) |
对RDD 采样,以及是否替换 |
rdd.sample(false, 0.5) |
非确定的 |
- 两个 RDD {1,2,3},{3,4,5}的 RDD 的转化操作
| union() |
生成一个包含两个RDD 中所有元
素的RDD |
rdd.union(other) |
{1, 2, 3, 3, 4, 5} |
| intersection() |
求两个RDD 共同的元素的RDD |
rdd.intersection(other) |
{3} |
| subtract() |
移除一个RDD 中的内容(例如移
除训练数据) |
rdd.subtract(other) |
{1, 2} |
| cartesian() |
与另一个RDD 的笛卡儿积 |
rdd.cartesian(other) |
{(1, 3), (1, 4), ...
(3, 5)} |
行动操作
reduce() 与 reduceByKey()
例程
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
public class SimpleReduce {
public static void main(String[] args) {
SparkConf sc = new SparkConf().setAppName("Contains");
JavaSparkContext javaSparkContext = new JavaSparkContext(sc);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> originRDD = javaSparkContext.parallelize(data);
Integer sum = originRDD.reduce((a, b) -> a + b);
System.out.println(sum);
//reduceByKey,按照相同的key进行reduce操作
List<String> list = Arrays.asList("key1", "key1", "key2", "key2", "key3");
JavaRDD<String> stringRDD = javaSparkContext.parallelize(list);
//转为key-value形式
JavaPairRDD<String, Integer> pairRDD = stringRDD.mapToPair(k -> new Tuple2<>(k, 1));
List list1 = pairRDD.reduceByKey((x, y) -> x + y).collect();
System.out.println(list1);
}
}
运行结果
...
19/09/17 17:08:37 INFO DAGScheduler: Job 0 finished: reduce at SimpleReduce.java:21, took 0.480038 s
15
...
19/09/17 17:08:38 INFO DAGScheduler: Job 1 finished: collect at SimpleReduce.java:29, took 0.237601 s
[(key3,1), (key1,2), (key2,2)]
...
aggregate()
例程
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import java.io.Serializable;
import java.util.Arrays;
import java.util.List;
public class AvgCount implements Serializable {
private AvgCount(int total, int num) {
this.total = total;
this.num = num;
}
private int total;
private int num;
pri