什么是布隆过滤器?
它实际上是一个很长的二进制向量和一系列随机映射函数。把一个目标元素通过多个hash函数的计算,将多个随机计算出的结果映射到二进制向量的位中,依次来间接标记一个元素是否存在于一个集合中。
布隆过滤器可以做什么?
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器特点
如果布隆过滤器显示一个元素不存在于集合中,那么这个元素100%不存在与集合当中
如果布隆过滤器显示一个元素存在于集合中,那么很有可能存在,可能性取决于对布隆过滤器的定义(BF.RESERVE {key} {error_rate} {capacity})
布隆过滤器的原理图,这个就很容易理解了。
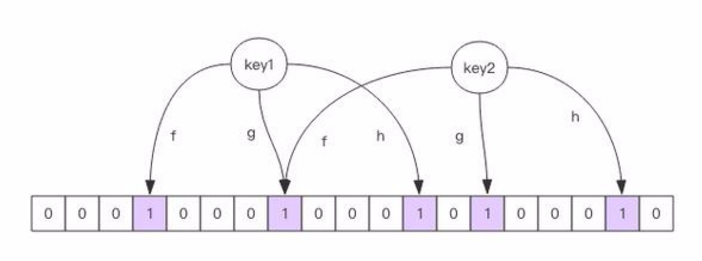
Redis中的布隆过滤器实现(rebloom模块扩展)
下载并编译
git clone git://github.com/RedisLabsModules/rebloom
cd rebloom
make
配置文件中加载rebloom
loadmodule /your_path/rebloom.so
重启Redis服务器即可
./bin/redis-cli -h 127.0.0.1 -p 6379 -a ****** shutdown
./bin/redis-server redis.conf
rebloom在Redis中的使用
bloom filter定义
BF.RESERVE {key} {error_rate} {capacity}
使用给定的期望错误率和初始容量创建空的Bloom过滤器(如果不存在的话)。如果打算向Bloom过滤器中添加许多项,则此命令非常有用,否则只能使用BF.ADD 添加项。
初始容量和错误率将决定过滤器的性能和内存使用情况。一般来说,错误率越小(即对误差的容忍度越低),每个过滤器条目的空间消耗就越大。
bloom filter基本操作
1,BF.ADD {key} {item}
单条添加元素
向Bloom filter添加一个元素,如果该key不存在,则创建该key(过滤器)。
如果项是新插入的,则为“1”;如果项以前可能存在,则为“0”。
2,BF.MADD {key} {item} [item...]
批量添加元素
布尔数(整数)的数组。返回值为0或1的范围的数据,这取决于是否将相应的输入元素新添加到过滤器中,或者是否已经存在。
3,BF.EXISTS {key} {item}
判断单个元素是否存在
如果存在,返回1,否则返回0
4,BF.MEXISTS {key} {item} [item...]
判断多个元素是否存在
布尔数(整数)的数组。返回值为0或1的范围的数据,这取决于是否将相应的元是否已经存在于key中。
127.0.0.1:8001> bf.reserve bloom_filter_test 0.0000001 1000000 OK 127.0.0.1:8001> bf.reserve bloom_filter_test 0.0000001 1000000 (error) ERR item exists 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.add bloom_filter_test key1 (integer) 1 127.0.0.1:8001> bf.add bloom_filter_test key2 (integer) 1 127.0.0.1:8001> 127.0.0.1:8001> bf.madd bloom_filter_test key2 key3 key4 key5 1) (integer) 0 2) (integer) 1 3) (integer) 1 4) (integer) 1 127.0.0.1:8001> bf.exists bloom_filter_test key2 (integer) 1 127.0.0.1:8001> bf.exists bloom_filter_test key3 (integer) 1 127.0.0.1:8001> bf.mexists bloom_filter_test key3 key4 key5 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001>
5,bf.insert
bf.insert{key} [CAPACITY {cap}] [ERROR {ERROR}] [NOCREATE] ITEMS {item…}
该命令将向bloom过滤器添加一个或多个项,如果它还不存在,则默认情况下创建它。有几个参数可用于修改此行为。
key:过滤器的名称
capacity:如果指定了,应该在后面加上要创建的过滤器的所需容量。如果过滤器已经存在,则忽略此参数。如果自动创建了过滤器,并且没有此参数,则使用默认容量(在模块级指定)。见bf.reserve。
error:如果指定了,后面应该跟随着新创建的过滤器的错误率(如果它还不存在)。如果自动创建过滤器而没有指定错误,则使用默认的模块级错误率。见bf.reserve。
nocreate:如果指定,表示如果过滤器不存在,就不应该创建它。如果过滤器还不存在,则返回一个错误,而不是自动创建它。如果需要在创建过滤器和添加过滤器之间进行严格的分离,可以使用这种方法。将NOCREATE与容量或错误一起指定是一个错误。
item:指示要添加到筛选器的项的开头。必须指定此参数。
127.0.0.1:8001> bf.insert bloom_filter_test2 items key1 key2 key3 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001> bf.insert bloom_filter_test2 items key1 key2 key3 1) (integer) 0 2) (integer) 0 3) (integer) 0 127.0.0.1:8001> bf.insert bloom_filter_test2 capacity 10000 error 0.00001 nocreate items key1 key2 key3 1) (integer) 0 2) (integer) 0 3) (integer) 0 127.0.0.1:8001> 127.0.0.1:8001> bf.insert bloom_filter_test2 capacity 10000 error 0.00001 nocreate items key4 key5 key6 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001>
bf持久化操作
对bloom过滤器进行增量保存。这对于不能适应常规save和restore模型的大型bloom filter非常有用。
第一次调用这个命令时,iter的值应该是0。这个命令将返回连续的(iter, data)对,直到(0,NULL),以表示完成
pyt