t['X[0]<=']=split
print(gini_result)
print(best_split)
3.1.3求误差
y1_=model[0].predict(X)#由v得到的预测结果小于v为1,大于v为-1
error1=(y!=y1_).mean()#求出预测值与实际值不相等元素的个数,并求平均
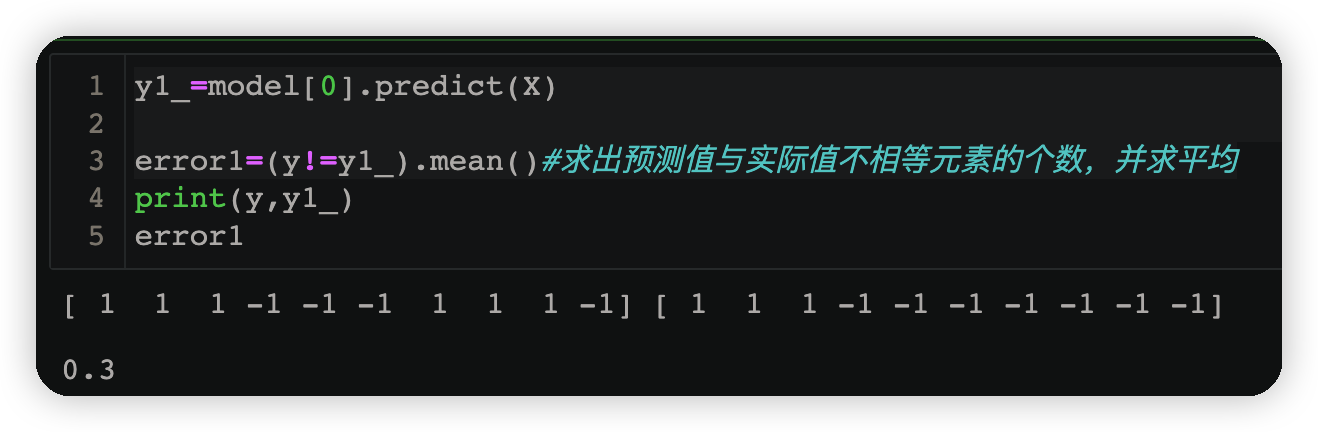
3.1.4计算第一个若学习器的权重
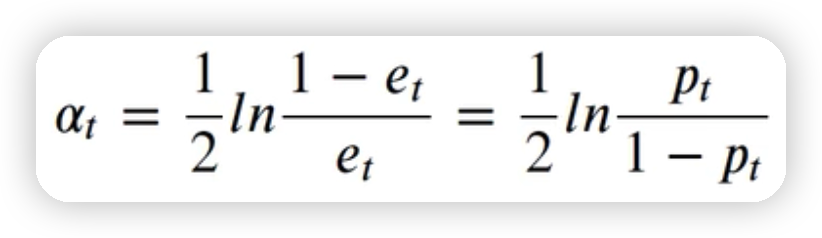
alpha_1=1/2*np.log((1-error1)/error1)
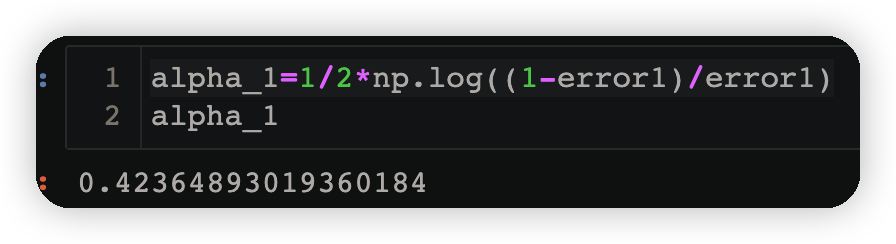
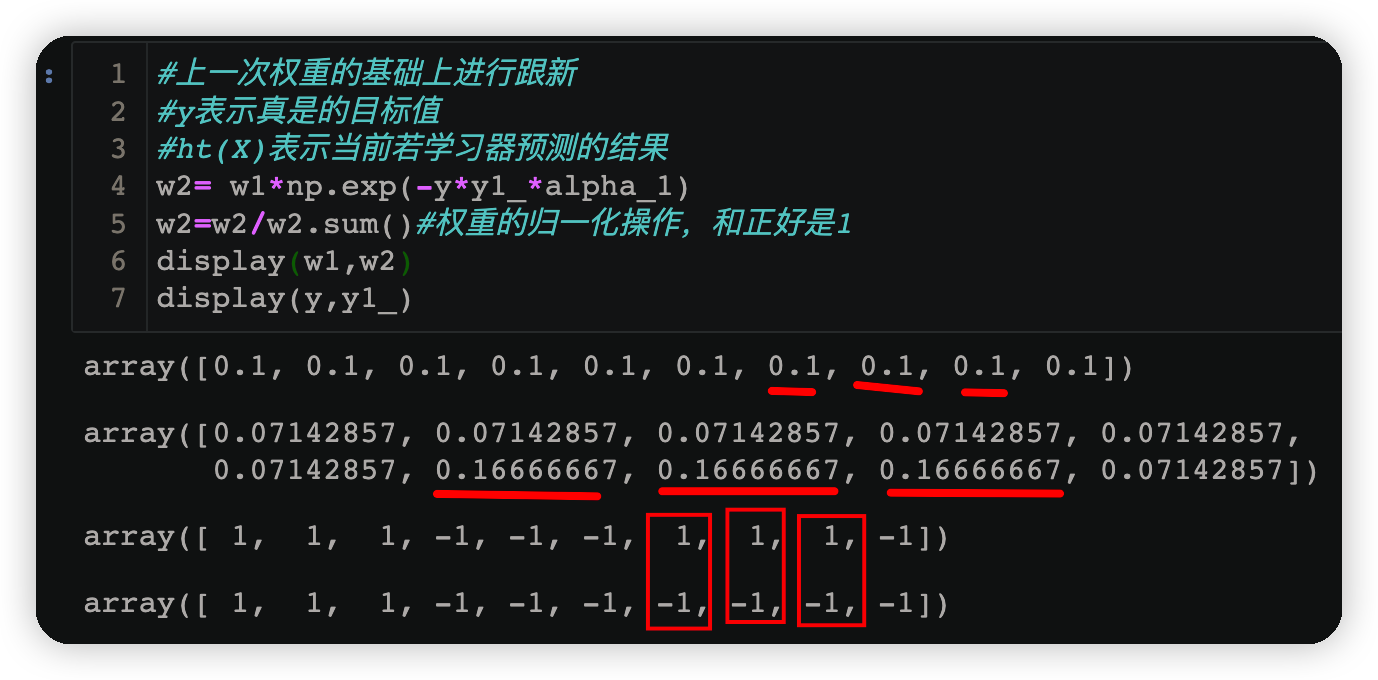
3.1.5 跟新样本权重
#上一次权重的基础上进行跟新
#y表示真是的目标值
#ht(X)表示当前若学习器预测的结果
w2= w1*np.exp(-y*y1_*alpha_1)
w2=w2/w2.sum()#权重的归一化操作,和正好是1
display(w1,w2)
display(y,y1_)
由下方运行结果可知当预测结果与原数据不相同时,该样本对应的权值也会随之增大;反之若预测正确则权值会减小
3.2第二轮的计算
也即第二课数的计算
cond=y==-1
np.round(w2[cond].sum(),3)#找到类别为-1的所有权值的和,四舍五入保留3位小数
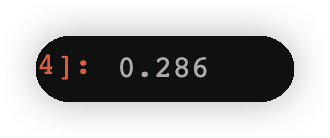
cond2=y==1
np.round(w2[cond2].sum(),3)

3.2.1 gini系数的计算
cond=y ==1 #类别1条件
p1 = w2[cond].sum()#使用新的样本权重分布
p2= 1-p1
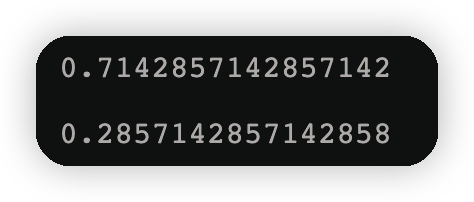
display(p1,p2)
gini=p1*(1-p1)+p2*(1-p2)
3.2.2拆分的条件
gini_result=[]
best_split={}#最佳分裂条件,X[0]<=8.5
lower_gini = 1#比较
for i in range(len(X)-1):#数组下标从0到9,10个数据一共要切九刀
split=X[i:i+2].mean()#裂开条件,就是假如一开始要将0和1裂开并取出
cond=(X<=split).ravel()#变成一维的,左边数据
left=y[cond]
right=y[~cond]#取反
#left_p=cond.sum()/cond.size#这种方式计算概率适用于每个样本的权重一样
left_p = w2[cond]/w2[cond].sum()#归一化,左侧每个样本在自己组内的概率
right_p=w2[~cond]/w2[~cond].sum()#归一化,右侧每个样本在自己组内概率
#左右两边的gini系数
gini_left=0
gini_right=0
for j in np.unique(y):#y表示类别
cond_left=left==j#左侧某个类别
p_left=left_p[cond_left].sum()#计算左边某个类别的概率
gini_left += p_left*(1-p_left)
cond_right=right==j#右侧某个类别
p_right=right_p[cond_right].sum()#计算右边某个类别的概率
gini_right += p_right*(1-p_right)
#左右两边的gini系数合并
p1=cond.sum()/cond.size#左侧划分数据所占的比例
p2=1-p1#右侧划分数据所占的比例
gini=gini_left*p1 +gini_right*p2
gini_result.append(gini)
if gini <lower_gini:
lower_gini=gini
best_split.clear()
best_split['X[0]<=']=split
print(gini_result)
print(best_split)

3.2.3计算误差
y2_ = model[1].predict(X)#根据求出来的v得到预测的结果
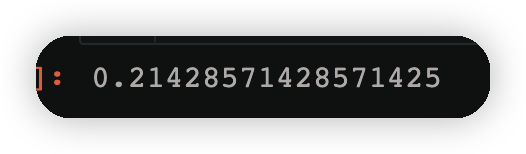
error2=((y != y2_)*w2).sum()
error2
3.2.4计算第二个弱学习器权重
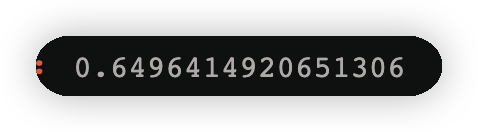
alpha_2=1/2*np.log((1-error2)/error2)
alpha_2
3.2.5跟新样本权重
#上一次权重的基础上进行更新
#y表示真是的目标值
#ht(X)表示当前若学习器预测的结果
w3= w2*np.exp(-y*y2_*alpha_2)
w3=w3/w3.sum()#权重的归一化操作,和正好是1
display(w2,w3)
display(y,y2_)

3.3第三轮计算
3.3.1 gini系数
cond=y ==1 #类别1条件
p1 = w3[cond].sum()#使用新的样本权重分布
p2= 1-p1
display(p1,p2)
gini=p1*(1-p1)+p2*(1-p2)
gini

3.3.2拆分条件
gini_result=[]
best_split={}#最佳分裂条件,X[0]<=2.5
lower_gini = 1#比较
for i in range(len(X)-1):#数组下标从0到9,10个数据一共要切九刀
split=X[i:i+2].mean()#裂开条件,就是假如一开始要将0和1裂开并取出
cond=(X<=split).ravel()#变成一维的,左边数据
left=y[cond]
right=y[~cond]#取反
#left_p=cond.sum()/cond.size#这种方式计算概率适用于每个样本的权重一样
left_p = w3[cond]/w3[cond].sum()#归一化,左侧每个样本在自己组内的概率
right_p=w3[~cond]/w3[~cond].sum()#归一化,右侧每个样本在自己组内概率
#左右两边的gini系数
gini_left=0
gini_right=0
for j in np.unique(y):#y表示类别
cond_left=left==j#左侧某个类别
p_left=left_p[cond_left].sum()#计算左边某个类别的概率
gini_left += p_left*(1-p_left)
cond_right=right==j#右侧某个类别
p_right=right_p[cond_right].sum()#计算右边某个类别的概率
gini_right += p_right*(1-p_right)
#左右两边的gini系数合并
p1=cond.sum()/cond.size#左侧划分数据所占的比例
p2=1-p1#右侧划分数据所占的比例
gini=gini_left*p1 +gini_right*p2
gini_result.append(gini)
if gini <lower_gini:
lower_gini=gini
best_split.clear()
best_split['X[0]<=']=split
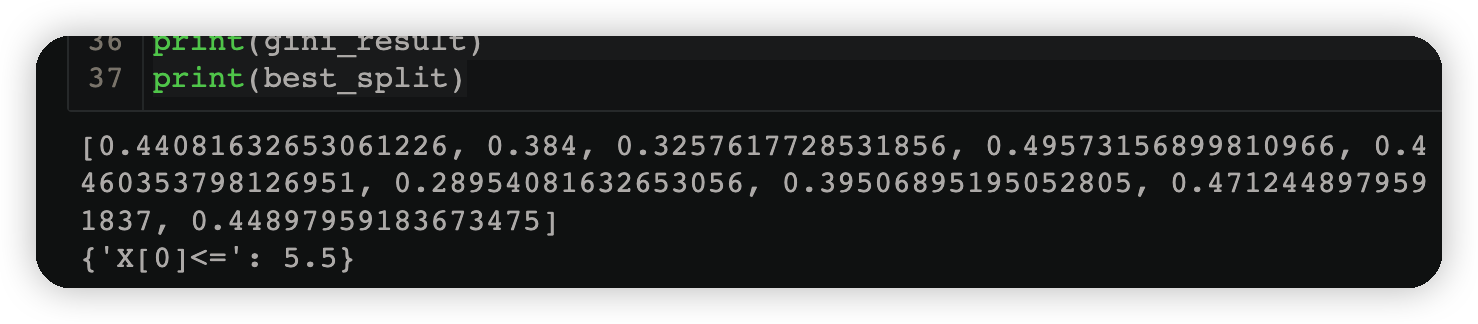
print(gini_result)
print(best_split)
3.3.3计算误差
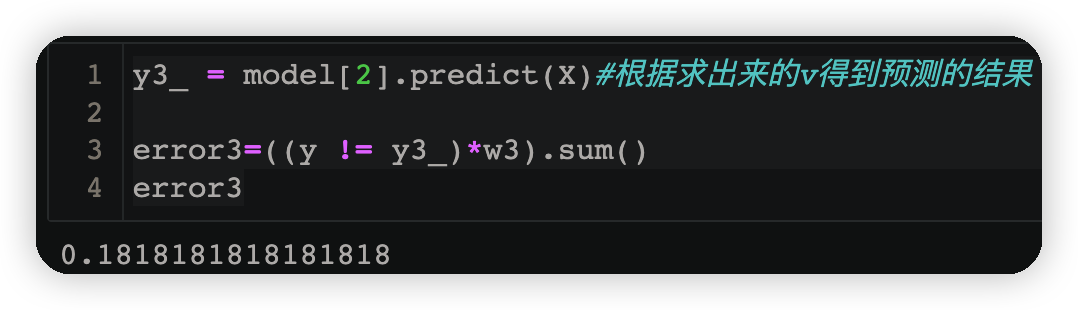
y3_ = model[2].predict(X)#根据求出来的v得到预测的结果
error3=((y != y3_)*w3).sum()
error3
3.3.4计算第三