... self.next_link = next_link
>>> link_3 = Link()
>>> link_2 = Link(link_3)
>>> link_1 = Link(link_2)
>>> link_3.next_link = link_1
>>> A = link_1
>>> del link_1, link_2, link_3
>>> link_4 = Link()
>>> link_4.next_link = link_4
>>> del link_4
# 回收不可达的 Link 对象 (和它的字典 __dict__)。
>>> gc.collect()
2
当垃圾收集器开始工作的时候,会将所有要扫描的容器对象放在第一个链表中,这样做是为了将所有不可达对象移除。因为正常情况下大多数对象都是可达的,所以移除不可达对象会涉及更少的指针操作,因此更高效。
算法开始的时候会为所有支持垃圾回收的对象另外初始化一个引用计数字段(下图中的 gc_ref),初始值设置为对象实际的引用计数。因为算法在识别循环引用的计算中会修改引用计数,通过使用一个另外的字段 gc_ref 解释器就不会修改对象真正的引用计数。
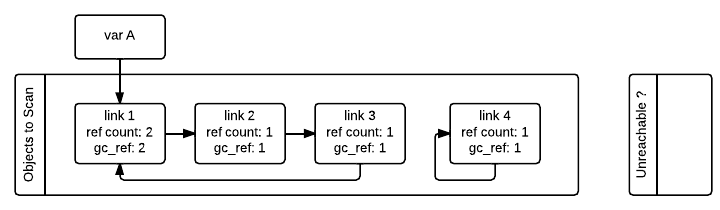
垃圾收集器会遍历第一个列表中的所有容器对象,每遍历一个对象都会将其所引用的所有的其他对象的 gc_ref 字段减 1。为了找到容器对象所引用的其他对象需要调用容器类的 tp_traverse 方法(通过 C API 实现或者由超类继承)。在遍历完之后,只有那些被外部变量引用的对象的 gc_ref 的值才会大于 0。
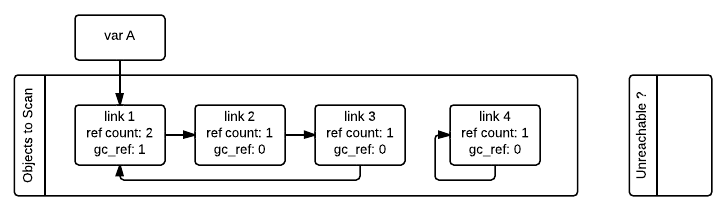
需要注意的是即使 gc_ref == 0 也不能说明对象就是不可达的。因为被外部变量引用的对象(gc_ref > 0)仍然可能引用它们。比如在我们的例子中,link_2 对象在第一次遍历之后 gc_ref == 0,但是 link_1 对象仍然会引用 link_2,而 link_1 是从外部可达的。为了找到那些真正不可达的对象,垃圾收集器需要重新遍历容器对象,这次遍历的时候会将 gc_ref == 0 的对象标记为暂时不可达并且移动到暂时不可达的链表中。下图描述了垃圾收集器在处理了 link_3 和 link_4 对象但是还没处理 link_1 和 link_2 对象时的状态。
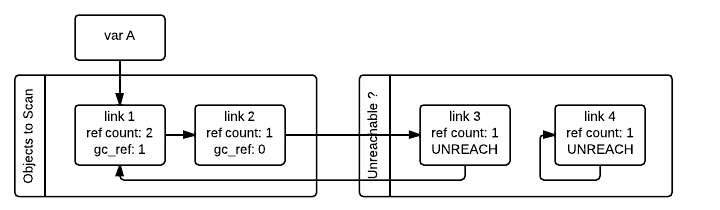
垃圾收集器接下来会处理 link_1 对象。由于 gc_ref == 1,垃圾收集器不会对其做特殊处理因为知道其可达(并且已经在可达对象链表中)。
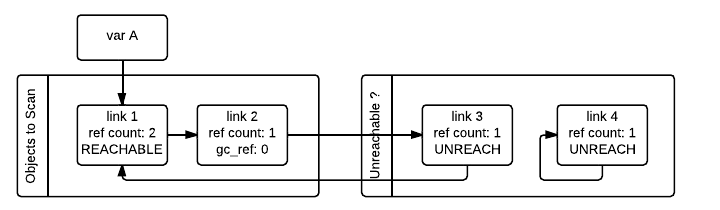
当垃圾收集器遇到可达对象时(gc_ref > 0),会通过 tp_traverse 找到其所引用的其他对象,并且将这些对象移动到可达对象链表(它们最初所在的链表)的末尾,同时设置 gc_ref 字段为 1。link_2 和 link_3 对象就会被这样处理,因为它们都被 link_1 引用。在上图所示状态之后,垃圾收集器会检查被 link_1 引用的对象从而知道 link_3 是可达的,所以将其移回到原来的链表中并且设置 gc_ref 字段值为 1,那么垃圾收集器下次遇到 link_3 的时候就知道它是可达的。为了避免重复处理同一个对象,垃圾收集器在处理被可达对象引用的对象的时候会标记它们已经被访问过(通过清除 PREV_MASK_COLLECTING 标记)。
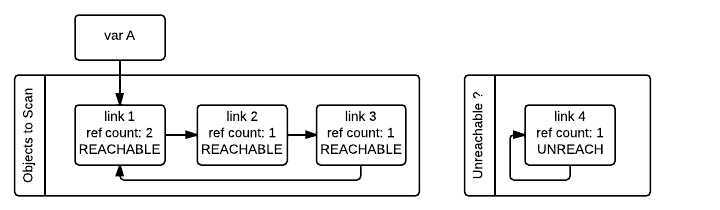
需要注意的是那些开始被标记为暂时性不可达后来又被移回到可达对象链表的对象,会再次被垃圾收集器访问到,因为按照算法逻辑现在被这些对象引用的其他对象也要被处理。第二次遍历实际上是对这些对象间引用关系构成的图的广度优先搜索。在第二遍遍历结束后,垃圾收集器就可以确定现在还留在暂时性不可达对象链表中的对象是真的不可达,因此可以被回收掉。
值得注意的是,整个算法中没有递归操作,也不需要相对于对象数量、指针数量或引用链长度的线性内存空间。除了临时的 C 变量占用 O(1) 的常量空间外,对象本身的字段都已经包含了算法需要的所有数据。
为什么选择移动不可达的对象
因为大多数对象都是可达对象,因此移动不可达对象看起来很合理。但是真正的原因并非想象的那么简单。
假设我们依次创建了 A、B 和 C 三个对象,那么它们在第一代(译注:这里的第一代指的是分代回收)中的顺序就是创建顺序。如果 B 引用 A,C 引用 B,并且 C 有外部引用,那么在垃圾回收算法的第一轮遍历之后 A、B 和 C 的 gc_ref 值分别为 0、0 和 1,因为只有 C 是外部可达对象。
在算法的第二轮遍历中,会先访问 A,因为 gc_ref 为 0 会被移动到暂时性不可达对象链表中,B 也一样。当访问到 C 的时候会将 B 移回到可达对象链表中,当再次访问 B 的时候 A 也会被移回到可达对象链表中。
本可以不用移动,A 和 B 却来回移动了两次,为什么要这么做呢?如果算法直接移动可达对象的话,那么只用将 A、B 和 C 分别移动一次即可。这么做的关键是在垃圾回收结束的时候这几个对象在链表中的顺序依次为 C、B 和 A,与它们最初的创建顺序相反。在后续的垃圾回收中,它们不再需要做任何移动。因为大多数对象之间都没有循环引用,这样做只会在第一次垃圾回收的时候开销比较大,在后续的垃圾回收中能节省很多移动的开销。
销毁不可达对象
一旦垃圾收集器确定了最终的不可达对象列表,就开始销毁这些对象,销毁的大体过程如下
- 处理并且清除弱引用(如果有的话)。如果要销毁的不可达对象有弱引用的回调,那么需要处理回调函数。这个处理过程需要特别小心,因为一个小小的错误就可能让状态不一致的对象被复活或者被回调函数所调用的 Python 函数引用。如果弱引用对象本身也是不可达的(弱引用和其引用的对象在不可达的循环引用中),那么这个弱引用对象需要马上被清理并且不用调用回调函数。如果不马上清理的话,那么在后来调用
tp_clear 的时候会造成严重后果。当弱引用和其引用的对象都不可达的时候,那么两者都会被销毁,因此可以先销毁弱引用,这个时候其引用的对象还存在,所以可以忽略弱引用的回调。
- 如果对象有老版本的终结器(
tp_del)需要将其移到 gc.garbage 列表中。
- 调用不可达对象的终结器(
tp_finalize函数)并且标记这些对象已终结,避免对象被复活后或者在其他对象的终结器已经移除该对象的情况下重复调用 tp_finalize。
- 处理被复活的对象。如果有些不可达对象在上一步被复活,垃圾收集器需要重新计算出最终的不可达对象。
- 对于每个最终的不可达对象,调用
tp_clear 来打破循环引用使每个对象的引用计数都变成 0,从而触发基于引用计数的销毁逻辑。
优化:分代回收
为了避免每次垃圾回收的时候耗时太久,垃圾收集器使用了一个常用的优化:分代回收。分代回收有个前提假设,认为大多数对象的生命周期都很短,会在创建后很快就被回收。这个假设与现实中很多 Python 程序的情况一致,因为很多临时对象会被很快地创建和销毁。存活越久的对象越不容易因为不可达而被回收。
为了充分利用这一点,所有容器对象都会被分成三代中的某一代。每个新建的容器对象都处于第一代(generation 0)。上面描述的垃圾回收算法只在某一个具体的分代中进行,那些没有被回收的对象会进入下一代(generation 1),这一代中的对象相对于上一代执行垃圾回收的次数会更少。如果对象在新一代中仍然没有被回收就会移动到最后