Pyhton����ʵս - ץȡBOSSֱƸְλ���� �� ������ϴ
�㡢��л
��лBOSSֱƸ���Ȩ������Ƹ��Ϣ��ʹ����������αȽ�����˼���о�֮�á�
�������������ȡ www.zhipin.com ��վ�����²����ķ�����ѹ�����������Ǹ�⣬��û�� DDoS ��Σ������վ����˼��
2017-12-14 ����
������һҹ֮������ IP ���DZ����ˣ���ñ������ڼ����˾���Ʒ�����������ս��
һ��ץȡ��ϸ��ְλ������Ϣ
1.1 ǰ������
������Ҫ֪��ҳ��� id ����������ϸ�����ӣ��� Python������Scrapyʵս - ץȡBOSSֱƸ��Ƹ��Ϣ �У������Ѿ��õ���Ƹ��Ϣ�Ĵ���Ϣ�������и� pid �ֶξ�������Ψһ����ij����Ƹ��������ƴ����ϸ���ӵġ�
�ǰɣ�������һ�۾Ϳ������ˡ�
1.2 ����ҳ����
����ҳ����ͼ��ʾ
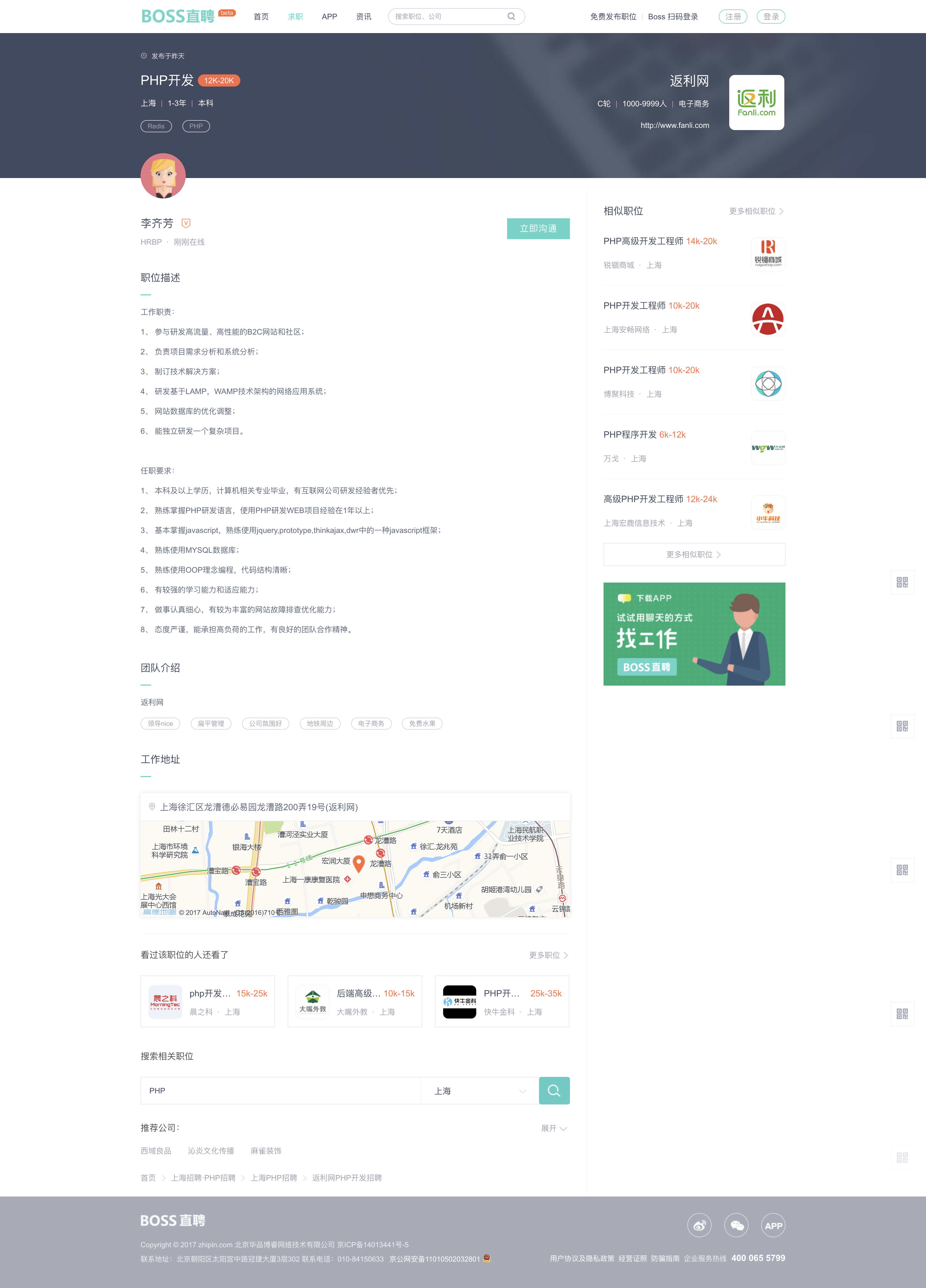
������ҳ�У��Ƚ���Ҫ�ľ���ְλ������������ַ������
������ҳ���������λְ������ְҪ������һ�� div �еģ�������ץ��ʱ��Ͳ�̫�÷֣�������Ҫ���������Ӥ�����ֿ�������
1.3 �����õ��Ŀ�
ʹ�õĿ���
- requests
- BeautifulSoup4
- pymongo
��Ӧ�İ�װ�ĵ��������£��Ͳ�ϸ˵��
1.4 Python ����
"""
@author: jtahstu
@contact: root@jtahstu.com
@site: http://www.jtahstu.com
@time: 2017/12/10 00:25
"""
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
from pymongo import MongoClient
headers = {
'x-devtools-emulate-network-conditions-client-id': "5f2fc4da-c727-43c0-aad4-37fce8e3ff39",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'dnt': "1",
'accept-encoding': "gzip, deflate",
'accept-language': "zh-CN,zh;q=0.8,en;q=0.6",
'cookie': "__c=1501326829; lastCity=101020100; __g=-; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l=%2F; __a=38940428.1501326829..1501326829.20.1.20.20; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502948718; __c=1501326829; lastCity=101020100; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502954829; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l=%2F; __a=38940428.1501326829..1501326829.21.1.21.21",
'cache-control': "no-cache",
'postman-token': "76554687-c4df-0c17-7cc0-5bf3845c9831"
}
conn = MongoClient('127.0.0.1', 27017)
db = conn.iApp # ����mydb���ݿ⣬û�����Զ�����
def init():
items = db.jobs_php.find().sort('pid')
for item in items:
if 'detail' in item.keys(): # ������ҵ��ٴ���ȡʱ����������ȡ����
continue
detail_url = "https://www.zhipin.com/job_detail/%s.html?ka=search_list_1" % item['pid']
print(detail_url)
html = requests.get(detail_url, headers=headers)
if html.status_code != 200: # ����̫����վ����403����ʱ�ȴ�����
print('status_code is %d' % html.status_code)
break
soup = BeautifulSoup(html.text, "html.parser")
job = soup.select(".job-sec .text")
if len(job) < 1:
continue
item['detail'] = job[0].text.strip() # ְλ����
location = soup.select(".job-sec .job-location")
item['location'] = location[0].text.strip() # �����ص�
item['updated_at'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # ʵʱ��ȡʱ��
res = save(item) # ��������
print(res)
time.sleep(40) # ͣͣͣ
# �������ݵ� MongoDB ��
def save(item):
return db.jobs_php.update_one({"_id": item['_id']}, {"$set": item})
if __name__ == "__main__":
init()���� easy����ѧ�߶��ܿ�����
1.5 �ن��¼���
�� ��һƪ���� ��ֻ������ �Ϻ�-PHP ��