1提高数据处理效率的迫切需要
本章包括
- 处理指数级增长的数据所面临的挑战
- 传统计算架构与最新计算架构的比较
- Python在现代数据分析中的作用和不足
- 提供高效Python计算解决方案的技术
我们一直在以极快的速度从各种来源收集海量数据。无论目前是否有使用价值,这些数据都会被收集起来。无论是否有办法对其进行处理、存储、访问或学习,数据都会被收集起来。在数据科学家对其进行分析之前,在设计师、开发人员和政策制定者利用其创造产品、服务和程序之前,软件工程师必须找到存储和处理这些数据的方法。现在,这些工程师比以往任何时候都更需要有效的方法来提高性能和优化存储。
在本书中,我将分享我在工作中使用的一系列性能和存储优化策略。简单地增加机器数量往往既不可能,也无济于事。因此,我在这里介绍的解决方案更多地依赖于理解和利用我们手头的东西:编码方法、硬件和系统架构、可用软件,当然还有Python语言、库和生态系统的细微差别。
Python已经成为一种首选语言,可以完成或至少粘合所有与数据洪流有关的繁重工作,这也是老生常谈的说法。事实上,Python在数据科学和数据工程领域的流行是该语言发展的主要推动力之一,根据大多数开发人员调查,Python已成为最流行的三大语言之一。在处理大数据方面,Python有其独特的优势和局限性,速度不够快肯定会带来挑战。好的一面是,正如您将看到的,有许多不同的角度、方法和变通办法可以让Python更高效地处理大量数据。
在找到解决方案之前,我们需要充分理解问题,而这正是我们在第一章中要做的事情。我们将花一些时间仔细研究大量数据带来的计算挑战,以确定我们所面对的问题到底是什么。接下来,我们将研究硬件、网络和云架构的作用,以了解为什么提高CPU速度等旧的解决方案不再适用。然后,我们将讨论Python在处理大数据时面临的特殊挑战,包括Python的线程和CPython的全局解释器锁(GIL)。一旦我们充分理解了需要新的方法来使Python性能更佳,我将概述您将在本书中学到的解决方案。
1.1 数据洪水有多严重?
您可能知道摩尔定律和埃德霍姆定律这两个计算定律,它们共同描绘了数据呈指数级增长,而计算系统处理这些数据的能力却滞后的戏剧性画面。埃德霍姆定律指出,电信领域的数据传输速率每18个月翻一番,而摩尔定律则预测,微芯片上可容纳的晶体管数量每两年翻一番。我们可以把埃德霍尔姆数据传输速率作为收集数据量的代表,把摩尔晶体管密度作为计算硬件速度和容量的指标。当我们把它们放在一起时,就会发现我们收集数据的速度和数量与我们处理和存储数据的能力之间存在六个月的差距。由于指数式增长很难用语言来理解,因此我将这两个定律对照绘制成一张图,如图1.1所示

摩尔定律和埃德霍尔姆定律之间的比率表明,硬件将始终落后于所产生的数据量。而且,随着时间的推移,这种差距会越来越大。
这张图描述的情况可以看作是我们需要分析的内容(埃德霍姆定律)与我们进行分析的能力(摩尔定律)之间的斗争。实际上,这幅图描绘的情况比我们的实际情况更为乐观。我们将在第 6 章讨论现代CPU架构中的摩尔定律时了解其中的原因。这里我们重点讨论数据增长,举一个例子,互联网流量是可用数据的间接衡量标准。如图1.2所示,多年来互联网流量的增长很好地遵循了埃德霍姆定律。
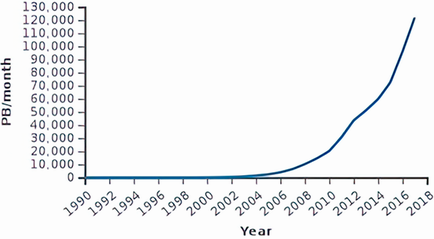
图 1.2 多年来全球互联网流量的增长(以每月 PB 为单位)。(资料来源:https://en.wikipedia.org/wiki/Internet_traffic)
此外,人类产生的 90% 的数据都发生在过去两年(参见"大数据及其意义",http://mng.bz/v1ya )。至于这些新数据的质量是否与其规模成正比,则完全是另一回事。问题是,产生的数据需要处理,而处理需要资源。
给软件工程师带来障碍的不仅仅是可用数据的数量。所有这些新数据的表现方式在本质上也在发生变化。有人预测,到2025年,大约80%的数据可能是非结构化数据("挖掘非结构化数据的力量",http://mng.bz/BlP0 )。我们将在本书稍后部分详细介绍,但简单地说,从计算角度来看,非结构化数据对数据处理的要求更高。
我们如何处理这些增长的数据?事实证明,我们大多没有这样做。据《卫报》(http://mng.bz/Q8M4 )报道,超过99%的数据从未被分析过。我们之所以无法利用如此多的数据,部分原因在于我们缺乏分析这些数据的有效程序。
数据的增长以及随之而来的对更多处理的需求,已发展成为有关计算的最恶毒的咒语之一: "如果你有更多的数据,只需投入更多的服务器"。出于多种原因,这往往不是一个可行或合适的解决方案。相反,当我们需要提高现有系统的性能时,我们可以审视系统架构和实施,找到可以优化性能的地方。我已经记不清有多少次在审查现有代码时,只需注意效率问题,就能将性能提高十倍。
需要明白的是,需要分析的数据量的增加与分析数据所需的基础设施的复杂性之间几乎不是线性关系。解决这些问题需要开发人员花费比机器更多的时间和智慧。这不仅适用于云环境,也适用于内部集群,甚至适用于单机实施。一些使用案例将有助于说明这一点。例如
您的解决方案只需要一台计算机,但突然您需要更多的机器。增加机器意味着你必须管理机器的数量,在它们之间分配工作负载,并确保数据被正确分区。您可能还需要一个文件系统服务器来增加机器数量。维护服务器群或云的成本要比维护单台计算机的成本高得多。
您的解决方案在内存中运行良好,但随着数据量的增加,已不再适合您的内存。要处理存储在磁盘中的新数据量,通常需要重新编写代码。当然,代码本身的复杂性也会增加。例如,如果主数据库现在在磁盘上,您可能需要创建缓存策略。或者,您可能需要从多个进程进行并发读取,或者更糟糕的是,并发写入。
在使用SQL数据库时,突然达到了服务器的最大吞吐能力。如果只是读取能力问题,那么只需创建几个读取副本就能解决。但如果是写入问题,该怎么办呢?也许你会建立分片,或者决定彻底改变你的数据库技术,转而使用一些所谓性能更好的 NoSQL 变体?
如果您依赖的是基于供应商专有技术的云系统,您可能会发现,无限扩展的能力更多是营销上的空谈,而不是技术上的现实。在许多情况下,如果您遇到性能限制,唯一现实的解决方案就是改变您正在使用的技术,而这种改变需要大量的时间、金钱和人力。
我希望这些例子能够说明,增长并不仅仅是"增加更多机器"的问题,而是需要在多个方面开展大量工作,以应对日益增加的复杂性。即使是在单台计算机上实施并行解决方案这样"简单"的事情,也会带来并行处理的所有问题(竞赛、死锁等)。这些更高效的解决方案会对复杂性、可靠性和成本产生巨大影响。
最后,我们可以提出这样的观点:即使我们可以线性扩展我们的基础设施(我们确实做不到),也需要考虑伦理和生态问题:据预测,与"数据海啸"相关的能源消耗占全球发电量的20%("数据海啸",http://mng.bz/X5GE ),而且随着硬件的更新,还存在垃圾填埋问题。
好消息是,在处理大数据时提高计算效率可以帮助我们减少计算费用、解决方案架构的复杂性、存储需求