作者 | 钱坤
钱坤,腾讯后台开发工程师,从事领域为流媒体CDN相关,参与腾讯TVideo平台开发维护。
原文是《Algorithmic Nuggets in Content Delivery》。这篇文章是akamai15年的文章,里面介绍了一些akamai在内容分发网络中的算法研究,下面对论文中的这些算法进行简单的总结。水平有限有限,有理解错误的还望指正。
ps:并不是所有的算法都已经投入到了实用阶段。
BLOOM FILTERS
Bloom filters的研究主要用在akamai的CDN中的两个场景:1)索引管理优化;2)内容过滤。
Bloom filters是hash算法的一个变种,有非常优秀的空间效率(使用位数组)和时间效率(插入的时间复杂度稳定为常数),但是会有一定的错误率。直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中。和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。其基本算法如下:
1)首先需要k个hash函数,每个函数可以把key散列成为1个整数
2) 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
3) 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1。
4) 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
通过一系列balabala的数学证明,可以得出最优hash函数个数k、位数组的位数m、存储的最元素数n关系如下:

再通过一系列balabala的数学证明,可以得出正向错误率、位数组的位数m、存储的最元素数n关系如下:
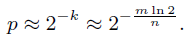
根据这两个公式,可以进行参数调整以达到预期目标。Bloom filters的主要场景如下:
1)索引管理优化:有些cache系统的索引查询可能由于访问慢设备导致查询操作较慢,可以在索引查询之前用使用Bloom filters搭建一层索引cache提升索引查询速度,如果Bloom filters中无法查到该文件,则认为该文件不存在,如果Bloom filters中可以查到该文件,则请求索引系统。在这种场景中由于存在元素删除操作,Bloom filters不能使用位数组,每一位需要用一个数字变量来代替,当多个文件共用一位时使用递增。
2)内容过滤:akamai统计了一个server cluster两天中web文件访问次数,如下图,可以发现,在总共4亿左右的文件中,有74%的文件仅被访问过一次,90%文件访问次数少于4次。
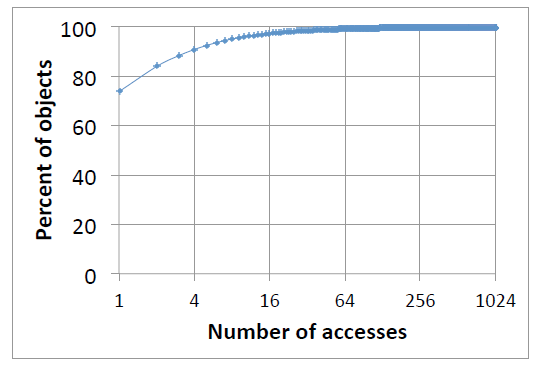
仅有单次访问的文件是没有必要落盘的,对于这种文件落盘会占用磁盘io和存储,并且可能会将更热的文件挤掉,进而降低cache命中率导致回源带宽增高。
以此为基础,akamai实现了“Cache-on-second-hit rule.”算法,即文件被第二次访问才落盘,而记录是否有过第一次访问所使用的算法就是Bloom filters。
由于cdn上被访问的文件数趋近于无穷,所以可以使用两个Bloom filters交替来记录文件第一次被访问,当第一个Bloom filters已经到了能记录的上限,就使用第二个Bloom filters,如果第二个也到了上限,则清空第一个Bloom filters重新使用第一个,每次查询文件是否曾经被访问需要查询两个Bloom filters。
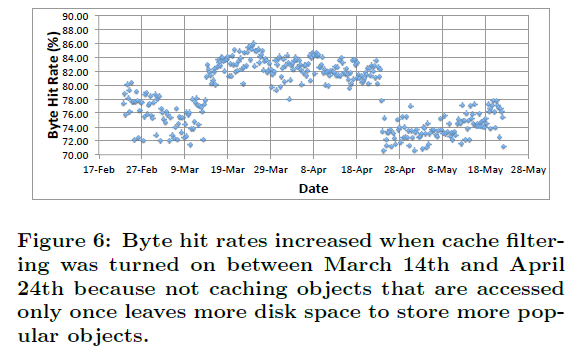
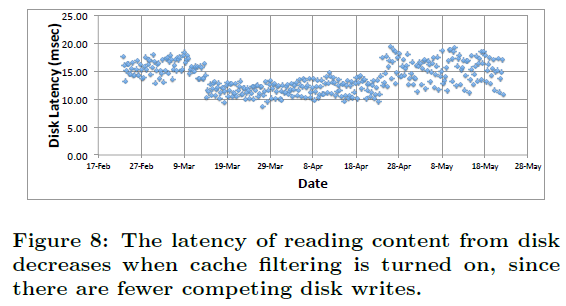
Akamai实现了这个组件之后在测试环境进行了测试,从下面的测试结果来看,测试环境缓存命中率从74%上升到了83%,磁盘写数据量下降了44%,磁盘操作时延下降了24%。

稳定分配问题
稳定分配问题的研究主要被用于全局负载均衡。
在cdn中的网络中可以抽象出两个概念。
1)map unit,map unit包含两个元素,第一个元素是用户ip的集合,第二个元素是map unit的类型(比如video、web等)
2)server cluster,akamai的服务器集群最小单位是cluster,一个cluster中包含若干服务器。通过对map unit和server cluster进行稳定分配,可以实现全局负载均衡。
Akamai对Gale-Shapley算法进行研究拓展以用于解决全局负载均衡问题。标准的Gale-Shapley算法是被提出用来解决“稳定婚姻问题”的:为n个男性和n个女性互相找到最合适的配偶。算法的基本思路为,先对所有男士进行落选标记,称其为自由男。且每个男士和每个女士均有一份排序,在排序中标记心仪的异性排名。当存在自由男时,进行以下操作:
(1)每一位自由男在所有尚未拒绝她的女士中选择一位被他排名最优先的女士;
(2)每一位女士将正在追求她的自由男与其当前男友进行比较,选择其中排名优先的男士作为其男友,即若自由男优于当前男友,则抛弃前男友;否则保留其男友,拒绝自由男。
(3)若某男士被其女友抛弃,重新变成自由男。
把这个算法基于以下的点进行拓展用于对map unit和server cluster进行匹配,也就是全局负载均衡。
(1)map unit和server cluster数目并不相等。在正常的cdn场景中,map unit的数目是要多于server cluster的数目。
(2)排序列表可以不完整。没有必要建立一个map unit到所有的server cluster的性能分数排序,只需要选择出该用户组可能被调度到的服务器集群并进行打分排序即可。
(3)每个server cluster拥有不确定的任意的容量。估算server cluster的容量,并让它为多个用户组进行服务。
有了拓展的Gale-Shapley算法作为框架,再对机器的资源进行细化,一个server cluster中一台机器的资源可以具体分为两种:网络资源和非网络资源(如内存、cpu能力等)。网络资源消耗用BPS来表示,非网络资源消耗用FPS来表示。那么可以用如下一个分层的资源树来对一个机器的资源进行表示:
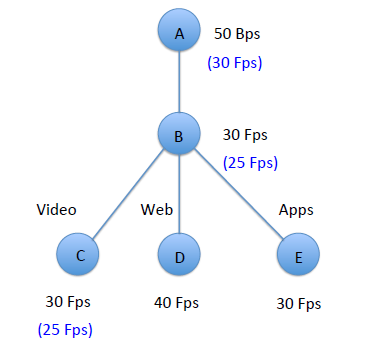
Node A代表机器的可用网络资源为50BPS,node B代表机器可用的非网络资源为30FPS,叶子节点代表不同的请求类型可以使用的FPS上限。
如果这时收到20单位video请求,每单位请求占用0.25FPS和1BPS,那么资源树剩余资源如上图中蓝字所示,node A剩余30BPS,node B剩余25 FPS,node C剩余25 FPS。
假设接下来收到26单位的web请求,每个请求消耗1FPS和0.2BPS,总共需要消耗26FPS和6.2BPS,这时发现当前机器的资源不足以承受全部的web请求,这时会根据Scoring(akamai用来评估客户端和服务器的服务性能的组件)的输出判断该cluster和哪种map unit之间有更好的性能,如果结果是更适合于服务新来的web请求,则按照Gale-Shapley算法会驱逐4单位的旧video请求,并接纳新来的web请求。反复进行这种驱逐操作可以让全局实现最优分配。
感觉这个算法在具体的实现细节上还存在着很多挑战。
一致性hash
一致性hash的研究被用来实现akamai的cdn局部负载均衡。感觉一致性hash应该和akamai有着千丝万缕的联系