cSearch。【从http://localhost:5601中进入】
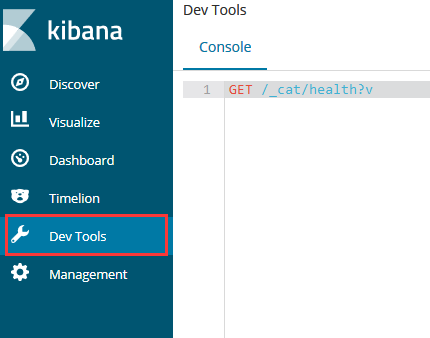
在输入命令GET /_cat/health?v后,点击该行右侧的执行按钮。【GET /_cat/health?v是查看集群的健康状态的命令】

然后就可以在右侧的结果窗口中查看命令执行结果。

【你现在大概都是看不懂命令的意义和结果的意义的了,不过你应该知道哪里输入命令和哪里看执行结果了】
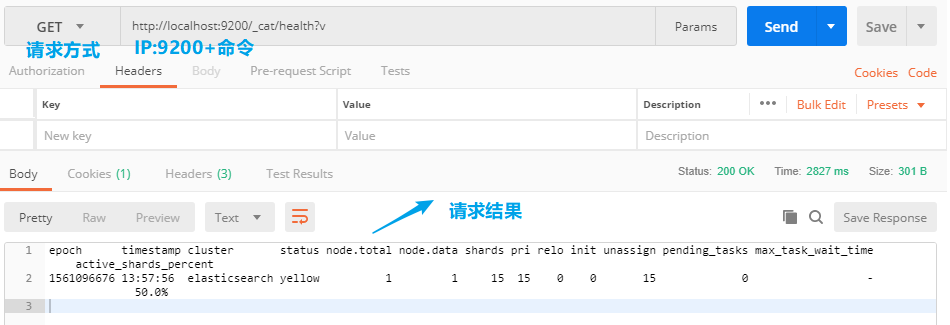
基于postman操作
postman是一个用来发请求的软件,可以使用restful风格的请求来操作elasticsearch。
比如上面的查看集群的命令:GET /_cat/health?v
转成基于restful的是:http://localhost:9200/_cat/health?v即IP:9200+命令,其中9200是用于接收restful请求的es监听端口。
补充:
上面的第一次使用并没有涉及到具体的知识,只是让你熟悉一下如何使用Kibana来操作ElasticSearch。下面讲到具体知识点才会具体使用。
小节总结
- 1.讲了ES如何提供服务:9200,9300
- 2.讲了如何下载、安装、运行ElasticSearch和Kibana
- 3.讲述了如何在Kibana中操作ElasticSearch
- 4.讲述了如何在postman中操作ElasticSearch
需要了解的概念
分布式模型相关
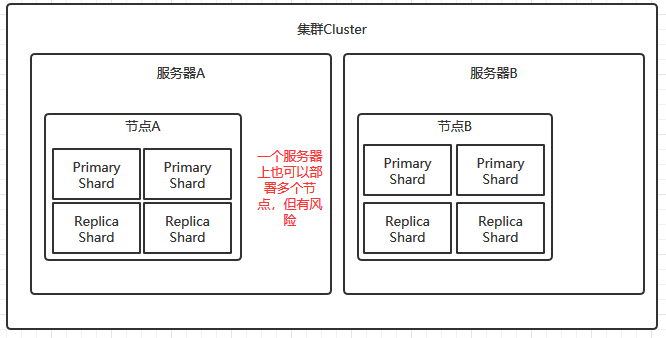
- 集群Cluster:所谓集群,就是多个服务节点的集合,集群意味着这些节点是能够相互交流的,不然无法进行数据交互。集群的默认名称是"elasticsearch",多个提供服务的节点会根据集群名来自动加入集群。
- 节点Node:节点是集群的一部分,是集群的最小单元,是可以提供服务的节点。
- 分片shard:分片位于节点上,分片是elasticsearch数据存储的单元,elasticsearch中的数据会存储在分片中。分片可以存储在任意一个节点上。分片分为主分片Primary Shard和副本分片Replica Shard。
- 主分片Primary Shard:当存储一个文档document的时候,会先存储到主分片中,然后再复制到其他的副本分片Replica Shard中。
- 副本分片Replica Shard:副本分片是主分片的复制(备份)。默认情况下,主分片有一个副本分片,主分片不能修改,但副本分片可以后续再增加。
- 为了保证数据的不丢失,通常来说Replica Shard不能与其对应的Primary Shard处于同一个节点中。【因为万一这个节点损坏了,那么存储在这个节点上的原数据(primary shard)和备份数据(replica shard)就全部丢失了】
- 当主分片挂掉的时候,会选择一个副本分片作为主分片。
- 查询可以在主分片或副本分片上进行查询,这样可以提供查询效率。【但数据的修改只发生在主分片上。】
- 一个Primary Shard可以有多个Replica Shard,默认创建是1个。
数据存储相关
数据存储在shard中,shard中的数据是以文档document为单位的。document存储在index和type划分的逻辑空间中。document以json为格式,每一个key-value中key可以称为域Field。
- 索引Index:索引是存储具有相同结构的document的集合,意义上有点类似关系型数据库中的数据库,用于存储一系列数据,比如可以说“商品”索引,一般都是个大类,小逻辑划分由Type处理。
- 类型Type:类型是索引的逻辑分区,意义有点类似关系型数据库中的数据表。用来划分索引下不同子类型的数据,比如商品(索引)可以有电子产品(类型),药品(类型)。在同一个分类下的数据一般都具有同种特征,用来定义数据的字段的数量一般也是相同的。每一个document都有一个type和一个id,在存储文档的时候需要指定索引、类型和ID。
- 文档Document:类似于关系型数据库中的记录,是ElasticSearch的数据存储的基本单位,格式与JSON相同。例如:
{
"book_id": 1,
"book_name": "Java Core ",
"book_desc": "A good book, you know!",
"category_id": "1",
"category_name": "Computer"
}
- 域Field:类似于关系型数据库中的字段。
- elasticsearch是面向restful的,下面是restful请求与elasticsearch操作的对应:
| GET |
读取 |
获取数据 |
| POST |
新增 |
新增数据 |
| PUT |
修改 |
修改数据或增加数据 |
| DELETE |
删除 |
删除数据 |
- 索引用来存储数据,分片也是用来存储数据,它们是怎么对应的?一个索引存储在多个分片上,默认情况下,一个索引有五个主分片,五个副本分片。主分片的数量一旦定下来就不能再修改,但副本分片的数量还可以修改。
小节总结
- 讲了一下ElasticSearch的集群概念,节点是集群的基础服务单位,节点可以提供数据读写服务,数据按分片来存储,主分片是主要数据,可以读取和修改数据,副本分片不支持修改数据。
- 主分片和副本分片的互斥性(为了保证数据不同时丢失)
- elasticsearch的数据的逻辑存储结构(索引->类型->文档)。索引是数据的大分类,类型是数据的小分类。
- 文档的格式
- 索引与分片的关系。一个索引存储在多个分片上
Hello ElasticSearch
前面提了一下index,type,document,说了ElasticSearch的逻辑存储空间。
下面以两个实例:“写document->读document”和“写document->搜索document“来初步演示一下如何存储数据和获取数据。
写->读
如果我们要向ElasticSearch中写入一份数据(document),命令的语法应该如下:
PUT /index名称/type名称/document的ID
{
document的数据
}
上面的语法的意思就是向一个index的一个type中插入一个document,document用id作为标识,后面我们取document的数据也将以这个id为依据。其中index,type是可以不需要我们预创建的,在我们还不会如何创建index和type的时候,你可以先随便打个名字(如果ElasticSearch检测到我们输入的index和type是不存在的,那么它就会以默认的规则帮我们创建出来)。
请在kibana的devtool中执行以下命令来存储一份document:
PUT /douban/book/1
{
"book_id":1,
"book_name":"A Clockwork Orange",
"author":"Antho