spark-windows����eclipse���ã��±��ؿ��������
>>>>>>ע�⣺�������JDK�İ�װ��JDKҪ����1.8�����ϰ汾,��ͨ�� java �Cversion�鿴��
һ��spark�����л����
Step1����װSpark
������http://spark.apache.org/downloads.htmlѡ����Ӧ�汾�����ذ�װ�����������µ���2.1.3�汾�����氲װ��Hadoop�汾��Ҫ��Spark�汾��Ӧ�����غ��Ҹ����ʵ��ļ��н�ѹ���ɡ������½���һ��home�ļ��У����·���spark, hadoop��ѹ���Ŀ¼��
other_jars ���������һЩ�Լ��������õ���jar��



��ѹ֮�����û�����������Spark���µ�bin�ļ����ڵ�Ŀ¼���ӵ�����������Path�����У�����HadoopҲһ����
����SPARK_HOME
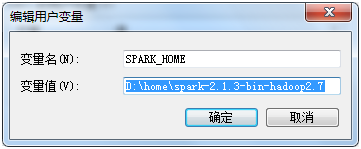
����PATH D:\home\spark-2.1.3-bin-hadoop2.7\bin;
Ҳ����ʹ��SPARK_HOME

������Spark���ǰ�װ�ɹ���
Step2����װHadoop
��http://mirrors.hust.edu.cn/apache/hadoop/common/������Ӧ�汾��Hadoop��װ�������µ���2.7.7�������Spark��Hadoop�汾��Ӧ���Ե����ϲ飬Spark��Hadoop�汾��һ�¿��ܻᵼ�³����⡣
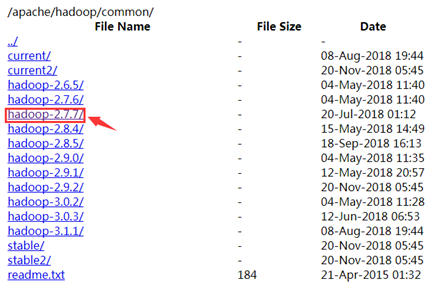
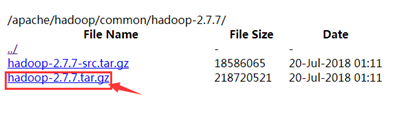
�����غõİ�װ�����н�ѹ��Ȼ��Hadoop�µ�binĿ¼���õ�Path�����С�
Ϊ�˷�ֹ���г����ʱ�����nullpoint�쳣����github���� winutils.exe ���ص�ַ��https://github.com/steveloughran/winutils
�ҵ���Ӧ��hadoop�汾��Ȼ�����binĿ¼�£�����winutils.exe, Ȼ���Ƶ�hadoop��binĿ¼�¡�

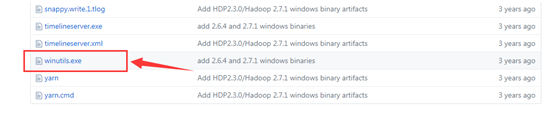
ϵͳ�����������ã�
HADOOP_HOME:

Path: $HADDOP_HOME$\bin

step3����װscala
������https://www.scala-lang.org/download/���ؾ���Ȼ��װ���ɡ�һ��Ĭ�ϻ��Զ����úû�����������װ��֮���cmd���ԣ�����scala�������������������װ�ɹ���(���ﰲװ����2.12.6�汾)

���û�гɹ������һ��Path���������������װ֮��û���Զ����ã����ֶ����ã�����Spark�Ļ������á�
����ͼ���ʾ�����л������óɹ�:

����eclipse����
2.1��ʹ��spark-assembly-*.jar������eclipse
�½�һ��java��Ŀ����spark-assembly-*.jar����Ϊ���̵ĵ���������������
2.2��ʹ�������úõ�Spark��������eclipse
spark2.0�Ժ�汾�����ṩspark-assembly-*.jar ����
��spark����Ŀ¼��jarsĿ¼��jar�����뼴�ɡ�
�ұ��ص�·����D:\home\spark-2.1.3-bin-hadoop2.7\jars
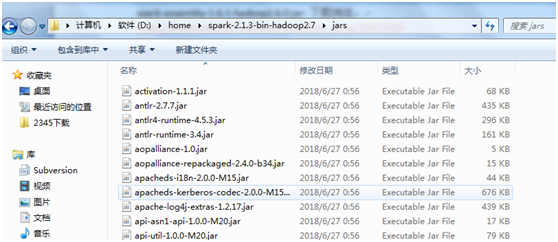
ע�⣺�÷��������ұ���û�гɹ�һֱȱ�ٸ���jar�����ұ���ʹ��2.1�ķ�����jar����·��Ϊspark-assembly-1.6.1-hadoop2.6.0.jar ���ص�ַ��
https://download.csdn.net/download/miss_peng/10472450
2.3������������һЩ����
2.3.1��System memory 259522560 must be at least 4.718592E8. Please use a larger heap size.
a�����⣺
��Eclipse�↑��spark��Ŀ������ֱ����spark�����г����ʱ�������������������
ERROR SparkContext: Error initializing SparkContext.
java.lang.IllegalArgumentException: System memory 468189184 must be at least 4.718592E8. Please use a larger heap size.
b������취��
��2���ط���������
1. �Լ���Դ���봦��������conf֮����ϣ�
val conf = new SparkConf().setAppName("word count")
conf.set("spark.testing.memory", "2147480000")//�����ֵ����512m����
2. ������Eclipse��Run Configuration������һ����Arguments��������VMarguments����������������һ��(ֵҲ��ֻҪ����512m����)
-Dspark.testing.memory=1073741824
�����IJ�����Ҳ���Զ�̬�����������ã�����-Dspark.master=spark://hostname:7077
�����оͲ��ᱨ��������ˡ�
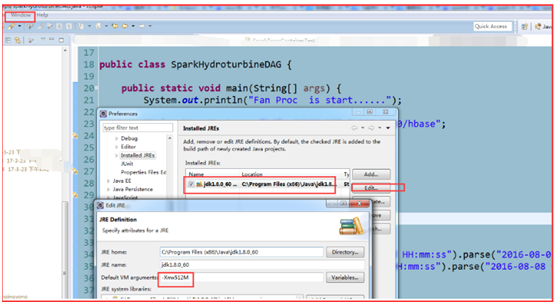
�����
1)��Window����Preference����Java����Installed JREs����ѡ��һ��Jre ��
2)��Edit��Default VM arguments ����룺-Xmx512M
2.4 ���Գɹ�jar����ͼ
����Ľ�ͼ��������һ̨���������õĻ������õ�jarĿ¼���������𣬵��Dz�Ӱ�졣

����ojdbc6.jar ��Ϊ���������ݿ�ʹ�õ�jar������Ҫ���ݲ�ͬ����������
2.5 �������Դ���
package spark.jdbc.oracle;
import java.math.BigDecimal;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Pa