什么是缓存(cache):
在项目中没有必要每次请求都查询数据库的情况就可以使用缓存,让每次请求先查询缓存,如果命中,就直接返回缓存结果,如果没有命中,就查询数据库, 并将查询结果放入缓存,下次请求时查询缓存命中,直接返回结果,就不用再次查询数据库。
缓存的作用?
缓和较慢存储的高频请求,缓解数据库压力,提升响应速率。
为什么缓存可以提高响应速度?
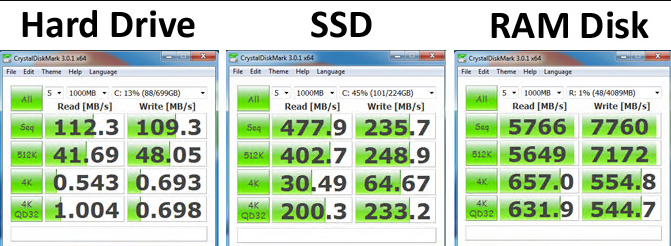
因为缓存时基于内存的存储的,内存的读写速率是普通SSD硬盘的至少十倍,更何况机械硬盘了:看对比图
缓存介质?
web项目中常用的缓存是memcached和redis,它们都支持分布式存储
缓存一定能给项目响应速率带来较大提升吗?
答案是不见得,要根据项目实际情况分析,有没有使用缓存的不要。在考虑使用缓存前,不妨先问问自己:
1. 项目的读写操作比例为多少,如果是写多读少,那缓存真的不一定能帮助你,此时不妨考虑数据库分库分表,然后做MySQL的分布式集群,或者简单直接,将硬盘全部替换为SSD(如果你的公司财大气粗),反之,以读为主的项目就比较适合加缓存了
2. 项目的访问频率高不高(用户多不多)?如果用户区区几千人或几万人,全然没有必要使用缓存,这点访问量经过网络后几乎不会造成并发,即使偶出现几万的并发,MySQL也是扛得住的,强行使用缓存反而会增加代码复杂度,甚至不容易维护,得不偿失。
3. 数据是否要求强一致性?如果项目涉及到金钱或者重要数据,且数据频繁发生变化,不允许存在一点差异,那是否使用缓存就要慎重慎重再慎重!因为缓存适用的是对数据一致性不是特别高的项目,如果使用,需要对缓存的设计有很好的方案,非常考验技术功底
说了这么多,进入正题吧,我们通过代码来模拟一下缓存的使用:
redis版本:
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 import functools 4 import redis 5 import time 6 import json 7 """ 8 使用redis做缓存,这里模拟一个web接口缓存的例子 9 """ 10 11 # 这里使用redis连接池,管理redisservice的所有连接,避免每次创建关闭连接的开销 12 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) 13 redis_cli = redis.Redis(connection_pool=pool) 14 15 def redis_cache(func): 16 @functools.wraps(func) # 为了保留原函数的属性,因为被装饰的函数对外暴露的是装饰器的属性 17 def wrapper(*args,**kargs): 18 start_time = time.time() 19 _key = 'function-name:{},args:{},kargs:{}'.format(func.__name__,args,kargs) #定义key的形式:函数名加与参数组成唯一的key 20 result = redis_cli.get(_key) 21 if result: # redis查找到对应的key,直接返回结果 22 result = json.loads(result) 23 print(type(result)) 24 print('redis find:{},result:{}'.format(_key,result)) 25 else: # redis没有查找到对应key,查询执行函数,查询mysql 26 print('redis not find:{}'.format(_key)) 27 result = func(*args,**kargs) 28 redis_cli.setex(_key,json.dumps(result),5) #将mysql结果写入redis,并设置过期时间 单位s 29 print("final result:{}".format(result)) 30 end_time = time.time()-start_time 31 print("Total time of this query:{}".format(end_time)) 32 return result 33 return wrapper 34 35 36 @redis_cache 37 def mysql_dispose(name,age): 38 time.sleep(2) 39 result = {'name:':name,'age':age} 40 print('mysql-result:{}'.format(result)) 41 return(result) 42 43 44 if __name__ == '__main__': 45 mysql_dispose('zz3',45) 46 47 48 out-put>>>: 49 第一次执行: 50 redis not find:function-name:mysql_dispose,args:('zz3', 45),kargs:{} 51 mysql-result:{'name:': 'zz3', 'age': 45} 52 final result:{'name:': 'zz3', 'age': 45} 53 Total time of this query:2.0049448013305664 54 55 第二次执行(距第一次5秒内执行): 56 <class 'dict'> 57 redis find:function-name:mysql_dispose,args:('zz3', 45),kargs:{},result:{'name:': 'zz3', 'age': 45} 58 Total time of this query:0.005013942718505859 59 60 第三次执行(5秒后)因为redis key过期被删除,所以无法命中,请求会再次查询数据库,然后添加缓存: 61 redis not find:function-name:mysql_dispose,args:('zz3', 45),kargs:{} 62 mysql-result:{'name:': 'zz3', 'age': 45} 63 final result:{'name:': 'zz3', 'age': 45} 64 Total time of this query:2.0038458017378002
不难看出,原本需要2秒才能完成的数据库查询动作,再有了redis缓存后可以直接返回结果,提高了响应速率
memcached版本(与上面代码大同小异,但是会有坑,注意红色标记部分)
#!/usr/bin/python # -*- coding: UTF-8 -*- import functools #要使用这个库,需要先安装:pip install Python-memcached import memcachei